
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в предложение FROM операторов SELECT, UPDATE и DELETE.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор. Отличительными особенностями операции соединения являются следующие:
- в схему таблицы-результата входят столбцы обеих исходных таблиц (таблиц-операндов), то есть схема результата является «сцеплением» схем операндов;
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы-операнда со строкой второй таблицы-операнда.
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
При необходимости соединения не двух, а нескольких таблиц, операция соединения применяется несколько раз (последовательно).
SQL-операция JOIN является реализацией операции соединения реляционной алгебры только в некотором приближении, поскольку в реляционной модели данных соединение выполняется над отношениями, которые являются множествами, а в SQL — над таблицами, которые являются мультимножествами. Результаты операций тоже, в общем случае, различны: в реляционной алгебре результат соединения даёт отношение (множество), а в SQL — таблицу (мультимножество).
Содержание
- Содержание
- Описание оператора [ править | править код ]
- Виды оператора JOIN [ править | править код ]
- INNER JOIN (внутреннее соединение)
- Написать запросы SQL с JOIN самостоятельно, а затем посмотреть решения
- LEFT OUTER JOIN (левое внешнее соединение)
- RIGHT OUTER JOIN (правое внешнее соединение)
- FULL OUTER JOIN (полное внешнее соединение)
- Псевдонимы соединяемых таблиц
- JOIN и соединение более двух таблиц
- CROSS JOIN (перекрестное соединение)
Содержание
Описание оператора [ править | править код ]
В большинстве СУБД при указании слов LEFT , RIGHT , FULL слово OUTER можно опустить. Слово INNER также в большинстве СУБД можно опустить.
В общем случае СУБД при выполнении соединения проверяет условие (предикат) condition. Если названия столбцов, по которым происходит соединение таблиц, совпадают, то вместо ON можно использовать USING . Для CROSS JOIN условие не указывается.
Для перекрёстного соединения (декартова произведения) CROSS JOIN в некоторых реализациях SQL используется оператор «запятая» (,):
Виды оператора JOIN [ править | править код ]
Для дальнейших пояснений будут использоваться следующие таблицы:
| Id | Name |
|---|---|
| 1 | Москва |
| 2 | Санкт-Петербург |
| 3 | Казань |
| Name | CityId |
|---|---|
| Андрей | 1 |
| Леонид | 2 |
| Сергей | 1 |
| Григорий | 4 |
INNER JOIN [ править | править код ]
Оператор внутреннего соединения INNER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
Описанный алгоритм действий является строго логическим, то есть он лишь объясняет результат, который должен получиться при выполнении операции, но не предписывает, чтобы конкретная СУБД выполняла соединение именно указанным образом. Существует несколько способов реализации операции соединения, например, соединение вложенными циклами (англ. inner loops join ), соединение хешированием (англ. hash join ), соединение слиянием (англ. merge join ). Единственное требование состоит в том, чтобы любая реализация логически давала такой же результат, как при применении описанного алгоритма.
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Сергей | 1 | 1 | Москва |
OUTER JOIN [ править | править код ]
Соединение двух таблиц, в результат которого обязательно входят все строки либо одной, либо обеих таблиц.
LEFT OUTER JOIN [ править | править код ]
Оператор левого внешнего соединения LEFT OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора важен, поскольку оператор не является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение левой и правой таблиц по предикату (условию) p.
- В результат включается внутреннее соединение ( INNER JOIN ) левой и правой таблиц по предикату p.
- Затем в результат добавляются те строки левой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие правой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Сергей | 1 | 1 | Москва |
| Григорий | 4 | NULL | NULL |
RIGHT OUTER JOIN [ править | править код ]
Оператор правого внешнего соединения RIGHT OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора важен, поскольку оператор не является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение левой и правой таблиц по предикату (условию) p.
- В результат включается внутреннее соединение ( INNER JOIN ) левой и правой таблиц по предикату p.
- Затем в результат добавляются те строки правой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие левой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Сергей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| NULL | NULL | 3 | Казань |
FULL OUTER JOIN [ править | править код ]
Оператор полного внешнего соединения FULL OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение первой и второй таблиц по предикату (условию) p. Слова «первой» и «второй» здесь не обозначают порядок в записи выражения (который неважен), а используются лишь для различения таблиц.
- В результат включается внутреннее соединение ( INNER JOIN ) первой и второй таблиц по предикату p.
- В результат добавляются те строки первой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие второй таблице, заполняются значениями NULL .
- В результат добавляются те строки второй таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие первой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Сергей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| NULL | NULL | 3 | Казань |
| Григорий | 4 | NULL | NULL |
CROSS JOIN [ править | править код ]
Оператор перекрёстного соединения, или декартова произведения CROSS JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Каждая строка одной таблицы соединяется с каждой строкой второй таблицы, давая тем самым в результате все возможные сочетания строк двух таблиц.
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Андрей | 1 | 2 | Санкт-Петербург |
| Андрей | 1 | 3 | Казань |
| Леонид | 2 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Леонид | 2 | 3 | Казань |
| Сергей | 1 | 1 | Москва |
| Сергей | 1 | 2 | Санкт-Петербург |
| Сергей | 1 | 3 | Казань |
| Григорий | 4 | 1 | Москва |
| Григорий | 4 | 2 | Санкт-Петербург |
| Григорий | 4 | 3 | Казань |
Если в предложении WHERE добавить условие соединения (предикат p), то есть ограничения на сочетания кортежей, то результат эквивалентен операции INNER JOIN с таким же условием:
Таким образом, выражения t1, t2 WHERE p и t1 INNER JOIN t2 ON p синтаксически являются альтернативными формами записи одной и той же логической операции внутреннего соединения по предикату p. Синтаксис CROSS JOIN + WHERE для операции соединения называют устаревшим, его не рекомендует стандарт SQL ANSI [1] [2] .
Оператор языка SQL JOIN предназначен для соединения двух или более таблиц базы данных по совпадающему условию. Этот оператор существует только в реляционных базах данных. Именно благодаря JOIN реляционные базы данных обладают такой мощной функциональностью, которая позволяет вести не только хранение данных, но и их, хотя бы простейший, анализ с помощью запросов. Разберём основные нюансы написания SQL-запросов с оператором JOIN, которые являются общими для всех СУБД (систем управления базами данных). Для соединения двух таблиц оператор SQL JOIN имеет следующий синтаксис:
После одного или нескольких звеньев с оператором JOIN может следовать необязательная секция WHERE или HAVING, в которой, также, как в простом SELECT-запросе, задаётся условие выборки. Общим для всех СУБД является то, что в этой конструкции вместо JOIN может быть указано INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN (или, как вариант, запятая).
INNER JOIN (внутреннее соединение)
Запрос с оператором INNER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON.

То же самое делает и просто JOIN. Таким образом, слово INNER — не обязательное.
Пример 1. Есть база данных портала объявлений. В ней есть таблица Categories (категории объявлений) и Parts (части, или иначе — рубрики, которые и относятся к категориям). Например, части Квартиры, Дачи относятся к категории Недвижимость, а части Автомобили, Мотоциклы — к категории Транспорт. Эти таблицы с заполненными данными имеют следующий вид.
| Part_ID | Part | Cat |
| 1 | Квартиры | 505 |
| 2 | Автомашины | 205 |
| 3 | Доски | 10 |
| 4 | Шкафы | 30 |
| 5 | Книги | 160 |
| Cat_ID | Cat_name | Price |
| 10 | Стройматериалы | 105,00 |
| 505 | Недвижимость | 210,00 |
| 205 | Транспорт | 160,00 |
| 30 | Мебель | 77,00 |
| 45 | Техника | 65,00 |
Заметим, что в таблице Parts Книги имеют Cat — ссылку на категорию, которой нет в таблице Categories, а в таблице Categories Техника имеет Cat_ID — первичный ключ, ссылки на который нет в таблице Parts. Требуется соединить данные этих двух таблиц так, чтобы в результирующей таблице были поля Part (Часть), Cat (Категория) и Price (Цена подачи объявления) и чтобы данные полностью пересекались по условию. Условие — совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts. Для этого пишем следующий запрос:
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
В результирующей таблице нет Книг, так как эта запись ссылается на категорию, которой нет в таблице Categories, и Техники, так как эта запись имеет внешний ключ в таблице Categories, на который нет ссылки в таблице Parts.
В ряде случаев при соединениях таблиц составить менее громоздкие запросы можно с помощью предиката EXISTS и без использования JOIN.
Написать запросы SQL с JOIN самостоятельно, а затем посмотреть решения
Есть база данных "Театр". Таблица Play содержит данные о постановках. Таблица Team — о ролях актёров. Таблица Actor — об актёрах. Таблица Director — о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).

Пример 2. Определить самого востребованного актёра за последние 5 лет.
Оператор JOIN использовать 2 раза. Использовать COUNT(), CURDATE(), LIMIT 1.
Пример 3. Вывести список актеров, которые в одном спектакле играют более одной роли, и количество их ролей.
Оператор JOIN использовать 1 раз. Использовать HAVING, GROUP BY.
Подсказка. Оператор HAVING применяется к числу ролей, подсчитанных агрегатной функцией COUNT.
LEFT OUTER JOIN (левое внешнее соединение)
Запрос с оператором LEFT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой по порядку (левой) таблицы, даже если они не соответствуют условию. У записей левой таблицы, которые не соответствуют условию, значение столбца из правой таблицы будет NULL (неопределённым).

Пример 4. База данных и таблицы — те же, что и в примере 1.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Parts, которые не соответствуют условию, пишем следующий запрос:
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
В результирующей таблице, в отличие от таблицы из примера 1, есть Книги, но значение столбца Цены (Price) у них — NULL, так как эта запись имеет идентификатор категории, которой нет в таблице Categories.
RIGHT OUTER JOIN (правое внешнее соединение)
Запрос с оператором RIGHT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из второй по порядку (правой) таблицы, даже если они не соответствуют условию. У записей правой таблицы, которые не соответствуют условию, значение столбца из левой таблицы будет NULL (неопределённым).

Пример 5. База данных и таблицы — те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| NULL | 45 | 65,00 |
В результирующей таблице, в отличие от таблицы из примера 1, есть запись с категорией 45 и ценой 65,00, но значение столбца Части (Part) у неё — NULL, так как эта запись имеет идентификатор категории, на которую нет ссылок в таблице Parts.
FULL OUTER JOIN (полное внешнее соединение)
Запрос с оператором FULL OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой (левой) и второй (правой) таблиц, даже если они не соответствуют условию. У записей, которые не соответствуют условию, значение столбцов из другой таблицы будет NULL (неопределённым).

Пример 6. База данных и таблицы — те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными как из таблицы Parts, так и из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
| NULL | 45 | 65,00 |
В результирующей таблице есть записи Книги (из левой таблицы) и с категорией 45 (из правой таблицы), причём у первой из них неопределённая цена (столбец из правой таблицы), а у второй — неопределённая часть (столбец из левой таблицы).
Псевдонимы соединяемых таблиц
В предыдущих запросах мы указывали с названиями извлекаемых столбцов из разных таблиц полные имена этих таблиц. Такие запросы выглядят громоздко: одно и то же слово повторяется несколько раз. Нельзя ли как-то упростить конструкцию? Оказывается, можно. Для этого следует использовать псевдонимы таблиц — их сокращённые имена. Псевдоним может состоять и из одной буквы. Возможно любое количество букв в псевдониме, главное, чтобы запрос после сокращения был понятен Вам самим. Общее правило: в секции запроса, определяющей соединение, то есть вокруг слова JOIN нужно указать полные имена таблиц, а за каждым именем должен следовать псевдоним таблицы.
Пример 7. Переписать запрос из примера 1 с использованием псевдонимов соединяемых таблиц.
Запрос будет следующим:
Запрос вернёт то же самое, что и запрос в примере 1, но он гораздо компактнее.
JOIN и соединение более двух таблиц
Реляционные базы данных должны подчиняться требованиям целостности и неизбыточности данных, в связи с чем данные об одном бизнес-процессе могут содержаться не только в одной, двух, но и в трёх и более таблицах. В этих случаях для анализа данных используются цепочки соединённых таблиц: например, в одной (первой) таблице содержится некоторый количественный показатель, вторую таблицу с первой и третьей связывают внешние ключи — данные пересекаются, но только третья таблица содержит условие, в зависимости от которого может быть выведен количественный показатель из первой таблицы. И таблиц может быть ещё больше. При помощи оператора SQL JOIN в одном запросе можно соединить большое число таблиц. В таких запросах за одной секцией соединения следует другая, причём каждый следующий JOIN соединяет со следующей таблицей таблицу, которая была второй в предыдущем звене цепочки. Таким образом, синтаксис SQL запроса для соединения более двух таблиц следующий:
Пример 8. База данных — та же, что и в предыдущих примерах. К таблицам Categories и Parts в этом примере добавится таблица Ads, содержащая данные об опубликованных на портале объявлениях. Приведём фрагмент таблицы Ads, в котором среди записей есть записи о тех объявлениях, срок публикации которых истекает 2018-04-02.
| A_Id | Part_ID | Date_start | Date_end | Text |
| 21 | 1 | ‘2018-02-11’ | ‘2018-04-20’ | "Продаю. " |
| 22 | 1 | ‘2018-02-11’ | ‘2018-05-12’ | "Продаю. " |
| . | . | . | . | . |
| 27 | 1 | ‘2018-02-11’ | ‘2018-04-02’ | "Продаю. " |
| 28 | 2 | ‘2018-02-11’ | ‘2018-04-21’ | "Продаю. " |
| 29 | 2 | ‘2018-02-11’ | ‘2018-04-02’ | "Продаю. " |
| 30 | 3 | ‘2018-02-11’ | ‘2018-04-22’ | "Продаю. " |
| 31 | 4 | ‘2018-02-11’ | ‘2018-05-02’ | "Продаю. " |
| 32 | 4 | ‘2018-02-11’ | ‘2018-04-13’ | "Продаю. " |
| 33 | 3 | ‘2018-02-11’ | ‘2018-04-12’ | "Продаю. " |
| 34 | 4 | ‘2018-02-11’ | ‘2018-04-23’ | "Продаю. " |
Представим, что сегодня ‘2018-04-02’, то есть это значение принимает функция CURDATE() — текущая дата. Требуется узнать, к каким категориям принадлежат объявления, срок публикации которых истекает сегодня. Названия категорий есть только в таблице CATEGORIES, а даты истечения срока публикации объявлений — только в таблице ADS. В таблице PARTS — части категорий (или проще, подкатегории) опубликованных объявлений. Но внешним ключом Cat_ID таблица PARTS связана с таблицей CATEGORIES, а таблица ADS связана внешним ключом Part_ID с таблицей PARTS. Поэтому соединяем в одном запросе три таблицы и этот запрос можно с максимальной корректностью назвать цепочкой.
Запрос будет следующим:
Результат запроса — таблица, содержащая названия двух категорий — "Недвижимость" и "Транспорт":
| Cat_name |
| Недвижимость |
| Транспорт |
CROSS JOIN (перекрестное соединение)
Использование оператора SQL CROSS JOIN в наиболее простой форме — без условия соединения — реализует операцию декартова произведения в реляционной алгебре. Результатом такого соединения будет сцепление каждой строки первой таблицы с каждой строкой второй таблицы. Таблицы могут быть записаны в запросе либо через оператор CROSS JOIN, либо через запятую между ними.
Пример 9. База данных — всё та же, таблицы — Categories и Parts. Реализовать операцию декартова произведения этих двух таблиц.
Запрос будет следующим:
Или без явного указания CROSS JOIN — через запятую:
Запрос вернёт таблицу из 5 * 5 = 25 строк, фрагмент которой приведён ниже:
| Cat_ID | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Стройматериалы | 105,00 | 1 | Квартиры | 505 |
| 10 | Стройматериалы | 105,00 | 2 | Автомашины | 205 |
| 10 | Стройматериалы | 105,00 | 3 | Доски | 10 |
| 10 | Стройматериалы | 105,00 | 4 | Шкафы | 30 |
| 10 | Стройматериалы | 105,00 | 5 | Книги | 160 |
| . | . | . | . | . | . |
| 45 | Техника | 65,00 | 1 | Квартиры | 505 |
| 45 | Техника | 65,00 | 2 | Автомашины | 205 |
| 45 | Техника | 65,00 | 3 | Доски | 10 |
| 45 | Техника | 65,00 | 4 | Шкафы | 30 |
| 45 | Техника | 65,00 | 5 | Книги | 160 |
Как видно из примера, если результат такого запроса и имеет какую-либо ценность, то это, возможно, наглядная ценность в некоторых случаях, когда не требуется вывести структурированную информацию, тем более, даже самую простейшую аналитическую выборку. Кстати, можно указать выводимые столбцы из каждой таблицы, но и тогда информационная ценность такого запроса не повысится.
Но для CROSS JOIN можно задать условие соединения! Результат будет совсем иным. При использовании оператора "запятая" вместо явного указания CROSS JOIN условие соединения задаётся не словом ON, а словом WHERE.
Пример 10. Та же база данных портала объявлений, таблицы Categories и Parts. Используя перекрестное соединение, соединить таблицы так, чтобы данные полностью пересекались по условию. Условие — совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts.
Запрос будет следующим:
Запрос вернёт то же самое, что и запрос в примере 1:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
И это совпадение не случайно. Запрос c перекрестным соединением по условию соединения полностью аналогичен запросу с внутренним соединением — INNER JOIN — или, учитывая, что слово INNER — не обязательное, просто JOIN.
Таким образом, какой вариант запроса использовать — вопрос стиля или даже привычки специалиста по работе с базой данных. Возможно, перекрёстное соединение с условием для двух таблиц может представляться более компактным. Но преимущество перекрестного соединения для более чем двух таблиц (это также возможно) весьма спорно. В этом случае WHERE-условия пересечения перечисляются через слово AND. Такая конструкция может быть громоздкой и трудной для чтения, если в конце запроса есть также секция WHERE с условиями выборки.
Разберем пример. Имеем две таблицы: пользователи и отделы.
Запрос вернет объединенные данные, которые пересекаются по условию, указанному в INNER JOIN ON .
В нашем случае условие . должен совпадать с .
В результате отсутствуют:
— пользователь Александр (отдел 6 — не существует)
— отдел Финансы (нет пользователей)
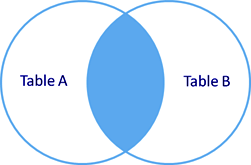
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Выбираются только совпадающие данные из объединяемых таблиц.
Чтобы получить данные, которые подходят по условию частично, необходимо использовать
внешнее объединение — OUTER JOIN.
Такое объединение вернет данные из обеих таблиц (совпадающие по условию объединения) ПЛЮС дополнит выборку оставшимися данными из внешней таблицы, которые по условию не подходят, заполнив недостающие данные значением NULL.
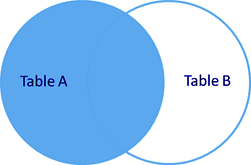
Существует два типа внешнего объединения OUTER JOIN — LEFT OUTER JOIN и RIGHT OUTER JOIN.
Работают они одинаково, разница заключается в том что LEFT — указывает что "внешней" таблицей будет находящаяся слева (в нашем примере это таблица users).
Ключевое слово OUTER можно опустить. Запись LEFT JOIN идентична LEFT OUTER JOIN.
Получаем полный список пользователей и сопоставленные департаменты.
в выборке останется только 3#Александр, так как у него не назначен департамент.
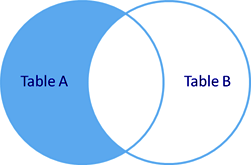
рис. Left outer join с фильтрацией по полю
RIGHT OUTER JOIN вернет полный список департаментов (правая таблица) и сопоставленных пользователей.
Дополнительно можно отфильтровать данные, проверяя их на NULL.
В нашем примере указав WHERE u.id IS null, мы выберем департаменты, в которых не числятся пользователи. (3#Финансы)
Все примеры вы можете протестировать здесь:
Cross/Full Join
FULL JOIN возвращает `объединение` объединений LEFT и RIGHT таблиц, комбинируя результат двух запросов.
CROSS JOIN возвращает перекрестное (декартово) объединение двух таблиц. Результатом будет выборка всех записей первой таблицы объединенная с каждой строкой второй таблицы. Важным моментом является то, что для кросса не нужно указывать условие объединения.
Дублирование строк при использовании JOIN
При использовании объединения новички часто забывают что результирующая выборка может содержать дублирующиеся данные!
Если вам нужна одна запись, делайте объединение с подзапросом
Self Join
Выборка из одной и той же таблицы для нескольких условий.
Рассмотрим задачку от яндекса:
Есть таблица товаров.
Она содержит следующие значения.
Напишите запрос, выбирающий уникальные пары `id` товаров с одинаковыми `name`, например:
При решении задачи необходимо учесть, что пары (x,y) и (y,x) — одинаковы.
SELECT g1. >, g2.id id2
— CONCAT(‘(‘, LEAST(g1.id, g2.id), ‘,’, GREATEST(g1.id, g2.id), ‘)’) row
FROM ya_goods g1
INNER JOIN ya_goods g2 ON g1.name = g2.name
WHERE g1. ><> g2.id
GROUP BY LEAST ( g1. >, g2. >) , GREATEST ( g1. >, g2. >)
ORDER BY g1. >;
— или без группировки (быстрее)
SELECT DISTINCT CONCAT ( ‘(‘ , LEAST ( g1. >, g2. >) , ‘,’ , GREATEST ( g1. >, g2. >) , ‘)’ ) row
FROM ya_goods g1
INNER JOIN ya_goods g2 ON g1.name = g2.name
WHERE g1. ><> g2.id
Объединяем таблицы ya_goods по одинаковому полю `name`, группируем по уникальным idентификаторам и получаем результат.
Множественное объединение multi join
Пригодится нам, если необходимо выбрать более одного значения из таблиц для нескольких условий.
Пример: набор вариантов (вес, объем) товаров.
Продукты в таблице products, Варианты — таблица product_options, Значения вариантов — таблица product2options
Необходимо: фильтровать продукты по дате, и имеющимся вариантам
CREATE TABLE `products` (
`id` int ( 11 ) ,
`title` varchar ( 255 ) ,
`created _ at` datetime
)
CREATE TABLE `product _ options` (
`id` int ( 11 ) ,
`name` varchar ( 255 )
)
CREATE TABLE `product2options` (
`product _ id` int ( 11 ) ,
`option _ id` int ( 11 ) ,
`value` int ( 11 )
)
INSERT INTO `products` ( `id` , `title` , `created _ at` ) VALUES
( 1 , ‘Кружка’ , ‘2009-01-17 20:00:00’ ) ,
( 2 , ‘Ложка’ , ‘2009-01-18 20:00:00’ ) ,
( 3 , ‘Тарелка’ , ‘2009-01-19 20:00:00’ ) ;
INSERT INTO `product _ options` ( `id` , `name` ) VALUES
( 11 , ‘Вес’ ) ,
( 12 , ‘Объем’ ) ;
INSERT INTO `product2options` ( `product _ id` , `option _ id` , `value` ) VALUES
( 1 , 11 , 200 ) ,
( 1 , 12 , 250 ) ,
( 2 , 11 , 35 ) ,
( 2 , 12 , 15 ) ,
( 3 , 11 , 310 ) ,
( 3 , 12 , 300 ) ,
( 2 , 11 , 45 ) ,
( 2 , 12 , 25 ) ;
Пример: выбрать товары,
добавленные после 17/01/2009 в следующих вариантах:
— вес=310, объем=300
— вес=35, объем=15
— вес=45, объем=25
— вес=200, объем=250
Просто перечислить условия вариантов в подзапросе/джоине через OR/AND не сработает,
необходимо осуществить объединение таблиц вариантов равное количеству этих самых вариантов (у нас — 2: объем и вес)
SELECT p. * , po1.name ‘P1’ , p2o1. value , po2.name ‘P2’ , p2o2. value
FROM products p
INNER JOIN product2options p2o1 ON p. >= p2o1.product_id
INNER JOIN product_options po1 ON po1. >= p2o1.option_id
INNER JOIN product2options p2o2 ON p. >= p2o2.product_id
INNER JOIN product_options po2 ON po2. >= p2o2.option_id
WHERE p.created_at > ‘2009-01-17 21:00’
AND ( — тарелка#3
p2o1.option_ >= 11 AND p2o1. value = 310
AND p2o2.option_ >= 12 AND p2o2. value = 300
OR — ложка#2
p2o1.option_ >= 11 AND p2o1. value = 35
AND p2o2.option_ >= 12 AND p2o2. value = 15
OR — ложка#2
p2o1.option_ >= 11 AND p2o1. value = 45
AND p2o2.option_ >= 12 AND p2o2. value = 25
OR — кружка#1 не попадает по дате
p2o1.option_ >= 12 AND p2o1. value = 250
AND p2o2.option_ >= 11 AND p2o2. value = 200
)
;
id title created_at P1 value P2 value
2 Ложка 2009-01-18 20:00:00 Вес 35 Объем 15
3 Тарелка 2009-01-19 20:00:00 Вес 310 Объем 300
2 Ложка 2009-01-18 20:00:00 Вес 45 Объем 25
— не попадает по дате
1 Кружка 2009-01-17 20:00:00 Объем 250 Вес 200
UPDATE и JOIN
Объединение можно использовать совместно с UPDATE.
Например, имеем таблицу houses (id, title, area). Нужно выбрать title, если в нем встречается `число м2`, заменить поле area, если оно меньше. Т.к. в mysql отстутсутствует поддержка регулярных выражений, нужно немного поколдовать с locate и substr.
В подзапросе выбираем интересующие нас данные, и в финальной стадии осуществляем обновление данных подходящий по критерию (p5 > area).
UPDATE houses base
INNER JOIN (
— Антарис аренда офиса 1594 м2, по ставке 12700 руб. м2/год -> 1594
SELECT
>,
@baseString := title title ,
@areaTitleEnd := LOCATE ( ‘ м2’ , @baseString ) as p2 ,
@tmpString := LTRIM ( REVERSE ( SUBSTR ( @baseString , 1 , @areaTitleEnd ) ) ) as p3 ,
@areaTitleBegin := LEFT ( @tmpString , — 1 + LOCATE ( ‘ ‘ , @tmpString ) ) as p4 ,
@ value := CAST ( REVERSE ( @areaTitleBegin ) as UNSIGNED ) as p5
FROM ga_pageviews
WHERE title like ‘ % м2 % ‘
) calc USING ( `id` )
SET base. area = calc.p5
WHERE base. area calc.p5
DELETE и JOIN
Рассмотрим пример с удалением дубликатов. Есть таблица tableWithDups (id, email). Нужно удалить строки с одинаковыми email:
Последние два примера не совместимы с ANSI SQL, но работают в mySQL.
За бортом статьи остались смежные объединениям (а также специфичные для определенных базданных темы):
SELF JOIN, FULL OUTER JOIN, CROSS JOIN (CROSS [OUTER] APPLY), операции над множествами UNION [ALL], INTERSECT, EXCEPT и т.д.
@tags: sql, mysql, sql server, oracle, sqlite, postgresql





