
В Microsoft SQL Server уже достаточно давно появилась технология In-Memory OLTP, которая позволяет хранить данные в памяти, за счет этого можно добиться значительного увеличения производительности. Сегодня в статье я расскажу Вам про эту технологию, а также покажу, как создаются таблицы, оптимизированные для памяти.
In-Memory OLTP – это технология, которая позволяет размещать таблицы с данными в памяти системы, при этом Вы можете обращаться к ним точно так же, как и к таблицам, которые расположены на диске. Данная технология предназначена для оптимизации производительности, иными словами, благодаря In-Memory OLTP можно в десятки раз увеличить производительность SQL инструкций.
Функционал In-Memory OLTP – это не отдельный компонент, который нужно устанавливать, это часть ядра Microsoft SQL Server, но он доступен только в редакции Enterprise и впервые появился в 2014 версии SQL сервера.
Таким образом, использовать возможности In-Memory OLTP в Microsoft SQL Server 2012 или более ранних версиях не получится. Так же, как и не получится использовать In-Memory OLTP в редакциях Standard или Express.
Когда только появилась технология In-Memory OLTP в Microsoft SQL Server 2014, она функционировала с большими ограничениями, в 2016 версии много ограничений было снято, а в 2017 версии функционал еще больше расширили, в следующих версиях улучшения в этом направлении, я думаю, также будут. Поэтому если Вы планируете активно применять технологию In-Memory OLTP, то приобретайте самую последнюю версию SQL Server.
Заметка! Все, что мы рассмотрим ниже, предполагает наличие у Вас базы знаний (основ) в части работы с языком T-SQL и Microsoft SQL Server в целом. Начинающим разработчикам рекомендую почитать мою книгу «Путь программиста T-SQL», в которой я подробно и максимально доступно рассказываю про язык T-SQL.
Содержание
- Пошаговое описание создания таблицы, оптимизированной для памяти
- Исходные данные
- Шаг 1 – Создание файловой группы для таблиц, оптимизированных для памяти
- Шаг 2 – Добавляем контейнер в файловую группу
- Шаг 3 – Создание таблицы, оптимизированной для памяти
- Шаг 4 – Работа с таблицей, оптимизированной для памяти
- Итоговый скрипт создания таблицы, оптимизированной для памяти в Microsoft SQL Server
- Автор: Вячеслав
- Итак, требования
- Немного теории
- Особенности Native Compiled процедур:
- Ограничение при работе с таблицами In-Memory:
- Общие ограничения для MS SQL 2014 и MS SQL 2016:
- Пример создания таблиц
- Наблюдение таблиц In-Memory
Пошаговое описание создания таблицы, оптимизированной для памяти
Сейчас мы пошагово рассмотрим все действия, которые необходимо выполнить, для того чтобы создать оптимизированную для памяти таблицу.
Примечание! Помните, что In-Memory OLTP доступна в редакции Enterprise, начиная с Microsoft SQL Server 2014.
Исходные данные
Для тестирования технологии In-Memory OLTP давайте создадим отдельную базу данных, в которой мы и будем создавать таблицы, оптимизированные для памяти. Для примера я создам DBInMemory.
Шаг 1 – Создание файловой группы для таблиц, оптимизированных для памяти
Для таблиц, оптимизированных для памяти, сначала необходимо создать специальную, оптимизированную для памяти файловую группу — MEMORY_OPTIMIZED_DATA. Давайте создадим для нашей тестовой базы данных файловую группу, оптимизированную для памяти, например, с названием FileGroupInMemory.
Шаг 2 – Добавляем контейнер в файловую группу
После создания специальной файловой группы, нам нужно добавить в нее контейнер для хранения файлов данных. В моем случае я добавляю контейнер FileInMemory, его расположение на диске D в каталоге DataBase.
Шаг 3 – Создание таблицы, оптимизированной для памяти
Чтобы создать таблицу, оптимизированную для памяти, необходимо использовать обычную инструкцию CREATE TABLE, но при этом нужно указать параметр MEMORY_OPTIMIZED=ON, иными словами, сказать SQL серверу о том, что мы хотим создать таблицу именно в памяти, а не на диске.
Мы можем создать таблицы, оптимизированные для памяти двух видов, на это влияет параметр DURABILITY:
- DURABILITY=SCHEMA_AND_DATA – таблица создается в памяти, но при этом дублируется на диске, чтобы в случае перезапуска SQL сервера все данные восстановились. Это поведение по умолчанию, поэтому в таких случаях параметр DURABILITY со значением SCHEMA_AND_DATA указывать необязательно;
- DURABILITY=SCHEMA_ONLY — таблица создается только в памяти, после перезагрузки SQL Server все данные будут утеряны.
Создание таблицы, оптимизированной для памяти, предполагает обязательное создание индекса, при этом можно использовать два вида индекса (Основы индексов в Microsoft SQL Server):
- хэш-индекс (появился одновременно с технологией In-Memory OLTP);
- некластеризованный индекс.
Также стоит учитывать и то, что на текущий момент таблицы, оптимизированные для памяти, не поддерживают следующие типы данных:
- datetimeoffset;
- geography;
- geometry;
- hierarchy >Для примера давайте создадим простую таблицу с тремя полями, которая будет храниться как в памяти, так и на диске, для того чтобы мы могли ее использовать постоянно, даже в случае перезапуска сервера.
Для одного поля мы создадим первичный ключ и некластеризованный индекс, здесь стоит понимать, что нам нужен именно некластеризованный индекс, так как, если помните, при создании обычной таблицы на диске с указанием первичного ключа по умолчанию создаётся кластеризованный индекс, поэтому в случае с таблицами в памяти мы принудительно указываем NONCLUSTERED.
Шаг 4 – Работа с таблицей, оптимизированной для памяти
С оптимизированными для памяти таблицами можно работать как с обычными таблицами, т.е. мы также можем писать инструкции SELECT, INSERT, UPDATE и DELETE. При этом стоит, конечно же, учитывать, что существуют определенные ограничения на использование некоторых конструкций языка Transact-SQL, например, нельзя использовать инструкцию TRUNCATE. Более подробно узнать о том, какие конструкции языка Transact-SQL не поддерживаются в In-Memory OLTP, можете посмотреть в официальной документации.
В качестве примера давайте добавим одну строку в оптимизированную для памяти таблицу и сделаем выборку, т.е. посмотрим на результат.
Итоговый скрипт создания таблицы, оптимизированной для памяти в Microsoft SQL Server
Сейчас я приведу итоговый скрипт, который выполняет все необходимые действия по созданию таблицы, оптимизированной для памяти, в него я также включил и инструкцию по созданию тестовой базы данных.
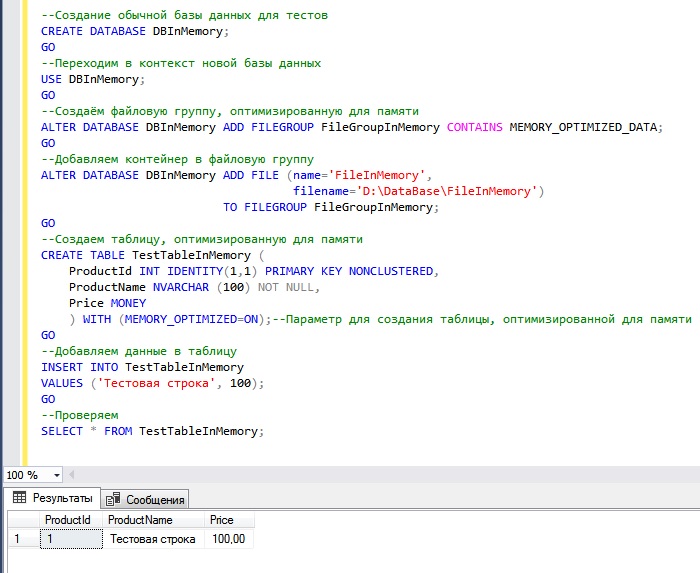
У меня все, надеюсь, материал был Вам интересен и полезен, пока!

Автор: Вячеслав
Начиная с MS SQL Server 2014 Microsoft предоставила к использованию технологию таблиц In-Memory, в 2016 данная технология получила продолжения и улучшения. Технология подразумевает, что определяется таблица, которая оптимизирована для нахождения в памяти сервера, что позволяет повысить производительность обработки данных в данной таблице, за счет быстроты работы данных в памяти и исключения задержек, связанные с вводомвыводом (хотя здесь есть свои нюансы). Постараюсь описать все нюансы и возможности в одной статье, чтобы не искать по разным страницам msdn, немного много, но зато все в одном.
Итак, требования
Чтобы вы могли в MS SQL Server использовать In-Memory таблицы, то должны проверить следующие требования:
— 64 – разрядный MS SQL Server 2014и выше редакции Enterprise, Developer или Evaluation
— достаточное объем самой оперативной памяти для данных и версионности строк, так же это зависит о нагрузки на использования таблиц в памяти
— Необходимо включить быструю инициализацию файлов, т.е предоставить учетной записи MSSQL Server право на «Perform volume maintenance tasks» в локальных политиках сервера. Это требования желательное, в противном случае может сыграть отрицательно на производительность.
Немного теории
Основным хранилищем для таблиц In-Memory является основная память, т.е вся память находится в памяти. Строки записываются и считываются только из памяти. Для отказоустойчивости данный таблиц дублируются на диск, но можно настроить, чтобы таблица была только в памяти, это не создает дополнительной нагрузки на диск, но и все данные в таблицах хранятся до перезагрузки сервера. Все операции с таблицами транзакционны и соответствуют классификации ACID(atomic, consistent, isolated, durable) . Транзакционность выполняется за счет версионность строк, т.е. каждая изменённая строка создает новую версию строки, к которой будет дальнейшее обращение. Это позволяет практически сократить блокировки в таблицах.
Одновременно с появлением In-Memory таблиц, появился новый тип индексов –HASH индексы. Создание HASH-индекса осуществляется с помощью внутренней hash функции, которая является единственной для всего ms sql server и является детерминированной, из этого следует, что несколько значений ключей индекса могут быть связаны с одним сопоставление хеш индекса, появляется конфликт хеша. Большое число конфликтов может отрицательно связаться на операции чтения. Использование hash индексов нужно быть аккуратным, они используются только когда в предикате условия указаны все поля hash индекса. К примеру: создали hash индекс на Имя, Фамилию, а в запросе используется только Фамилия, то наш Hash индекс работать не будет, нужно указать в Запросе и имя и Фамилию. Так же в HASH индексах запрещен поиск по диапазону.
На таблицах In-Memory могут быть определены индексы как кластерные, не кластерные, так и новые HASH индексы одновременно, возможно несколько HASH индексов. Единственное замечание: все индексы создаются при создании таблицы инструкцией CREATE TABLE, далее новые индексы создаются только через пересоздание таблицы.
Пример вполне можно создать данную таблицу:
В которой мы определили три индекса:
Кластерные по полю Id
Не кластерный [idx2]
Hash индекс [Hass_ind].
Так же существуют два вида таблиц: таблицы оптимизированные с параметром DURABILITY=SCHEMA_AND_DATA – это таблицы, которые размещены в памяти, но и существуют на диске, второй тип таблиц это таблицы с параметром DURABILITY = SCHEMA_ONLY, это значит , что данные находятся в памяти и доступны только до перезагрузки сервера, так же эти данные не будут доступны и при создание резервной копии, с параметром DURABILITY =SCHEMA_AND_DATA данные в таблице In-Memory будут доступны после восстановления из резервной копии.
Параметр WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) определяется для всей таблицы: вне зависимо есть ли в ней новые HASH индексы или кластерные, при значении параметра DURABILITY= SCHEMA_ONLY- данные хранятся до перезагрузки ms sql server.
Обращение к таблицам In-Memory происходит с помощью стандартных инструкций T-SQL с явным указанием уровня изоляции SNAPSHOT, REPETABLEREAD или SERIALIZABLE или помощью так называемых процедур скомпилированные в собственном коде (Native Compiled Stored Procedures). В обращение к таблицам In-Memory есть много ограничений, следует это учитывать.
Процедуры, скомпилированные в собственном коде (Native Compiled Stored Procedures) –это наиболее быстрый доступ к таблицам In-Memory, но и имеющий много особенностей. На «физическом» уровне после создания Native Compiled процедуры мы имеем dll библиотеку, которая компилируется один раз при создании или при рестарте сервера.
Особенности Native Compiled процедур:
— код процедуры определяется разово, далее ее можно изменить только через пересоздание
— внутри процедуры транзакция определяется как BEGIN ATOMIC , что определяет свои требования
— объекты, на которые ссылается процедура, не могут быть изменены при наличие данных процедур
— нельзя просмотреть актуальный план данных процедур
— нельзя получить статистику выполнения данных процедур
— для соединения таблиц внутри хранимой процедуры используется только NETED LOOP
— не используется параллелизм
— план выполнения Native Compiled процедуры определяется в момент ее создания, в MS SQL Server2016 для перекомпиляции процедуры можно использовать процедуру sp_recompile
Пример создания Native Compiled процедурs:
with native_compilation,schemabinding,execute as owner- При определение данной процедуры обязательно
begin atomic with (transaction isolation level = snapshot,language = N’English’ ) – так же обязательные параметры, требования ATOMIC
После создания данной процедуры в каталоге баз данных будет создана папка xtp далее папка номер базы данных, внутри которой будут файлы нашей процедуры:
xtp_t_9_2037582297_183184668414697.dll- сама dll библиотека
Содержимое которых вы можете посмотреть, оно связано с определением процедуры на коде C. Файлы вы можете изменитьудалить, но ms sql server придется их заново создать, что потребует время при вызове процедуры.
В имени файла выше 9 это номер базы данных, 2037582297 – номер объекта из sysobjects.
Кстати, выше процедура будет работать только в MS SQL Server 2016, т.к в MS SQL Server 2014 текстовые поля все должны быть в UNICOD формате. В MS SQL Server 2014 нужно немного поменять определение
иначе будет ошибка:
Ограничение при работе с таблицами In-Memory:
Ниже описаны наиболее явные ограничения в MS SQL Server на таблицы In-Memory, которые чаще всего мы привыкли использовать при обычных disk таблицах. Приведена только часть ограничений, полные ограничения можно изучить в msdn.
Общие ограничения для MS SQL 2014 и MS SQL 2016:
Для баз данных с таблицами In-Memory запрещены свойство AUTO_CLOSE
Запрещена операция CREATE DATABASE с параметром ATTACHE_REBUILD_LOG
Запрещена операция создания DATABASE SNAPSHOT
Операции проверки целостности DBCC CHECKDB, CHECKTABLE пропускают таблицы In-Memory
Не поддерживаются межбазовые запросы и транзакции, а также обращения со связанными серверами
Не поддерживаются вычисляемые столбцы в таблицах In-Memory
Не поддерживается репликация для таблиц In-Memory
Не поддерживаются столбцы SPARSE
Не поддерживаются операции TRUNCATE
Не поддерживается сжатие, секционирование таблиц
Не поддерживается репликация, зеркалирование
В Native Compiled процедурах Функции MIN и MAX не поддерживаются для типов nvarchar, char, varchar, varchar, varbinary и binary
В Native Compiled процедурах DISTINCT не поддерживается в предложении ORDER BY
В Native Compiled процедурах не поддерживаются WITH TIES и PERCENT в предложении TOP
В Native Compiled процедурах не поддерживается многостроковая вставка через INSERT.
В Native Compiled процедурах не поддерживается SELECT INTO
В Native Compiled процедурах не поддерживается инструкция CASE
Таблицы In-Memory с SCHEMA_ONLY в базах данных в группе доступности AlwaysOn будут пустыми.
Не поддерживаются типы данных: datetimeoffset, geography, geometry, hierarchyid, rowversion,xml, sql_variant, определяемые пользователем типы
Операция MERGE только в качестве назначения
Доступ из модулей CLR запрещен к таблицам In-Memory
Фильтруемые индексы не поддерживаются
Не поддерживаются курсоры в Native Compiled процедурах
Ограничения MS SQL 2014
все ограничения выше +
Использование только UNICOD типов данных
Использование Collation _Bin для символьных полей индексов
Ограничение общего объем всех таблиц в памяти не должен превышать 250 Гб
Не авто обновляется статистика для таблиц In-Memory, необходимо вручную обновлять
Не поддерживаются LOB объекты
Пример создания таблиц
Для начала нужно иметь базу данных, далее в базе данных создается файловая группы базы данных для таблиц In-Memory
Добавляем новый файл группы в нашу файловую группу для таблиц In-Memory
В этот момент в указанном каталоге создается каталог InMemoryFile с содержимым аналогично каталогу FileStream:
Далее создаем нашу таблицу:
Создали, ОК, далее. СТОП далее, нужно уточнить, что выше создалась таблица в MS SQL Server2016, в 2014 она не создается, т.к в 2014 в таблицах In-Memory возможно использовать только UNICODE типы данных
В 2014 создаем таблицу:
Таблица определена с одним hash индексом.
Немного об синтаксисе создания таблицы:
PRIMARY KEY NONCLUSTERED HASH – создается не кластерный HASH индекс, HASH индекс поддерживается только для In-Memory таблиц, без него мы не сможем создать нашу таблицу в памяти, обязательный параметр.
WITH (BUCKET_COUNT=1000000) – так же обязательный параметр при создание HASH индексов, указывается так называемые количество контейнеров для hash индексов, которое желательно должно быть в 2 раза более уникальных значений нашего индекса. Если выбрано неоптимальное значение то, может привести к деградации производительности при обращении к данной таблице.
Далее сделаем тест на загрузку данных.
Я сделал несколько простых тестов на вставку:
Использовал таблицы, созданные выше в пример создания таблицы,
структура во всех тестах была одинакова, за исключением менял параметр DURABILITY, а так же изменял поля в MS SQL Server2016.
| Parameters of Test | MS SQL Server 2014 | average val, sec | MS SQL Server 2016 | average val, sec |
| Table with DURABILITY = SCHEMA_AND_DATA | 585/584/584/588 | 585,25 | 626/637/610/616 | 622,25 |
| Table with DURABILITY = SCHEMA_AND_DATA with no UNICODE column, BIN | 610/604/585/606/ | 601,25 | ||
| Table with DURABILITY = SCHEMA_AND_DATA , UNICODE, не BINполе | 588/604/614/617 | 605,75 | ||
| Table with DURABILITY = SCHEMA_ONLY | 38/37/39 | 38 | 47/55/52 | 51,3 |
| Table with DURABILITY = SCHEMA_ONLY with no UNICODE column, BIN | 44/46/49 | 46,3 | ||
| Table with DURABILITY = SCHEMA_ONLY , UNICODE, не BIN поле | 53/50/52 | 51,7 | ||
| Native procedure with DURABILITY = SCHEMA_AND_DATA | 560/553/559 | 557,3 | 564/584/581 | 576,3 |
| Native procedure with DURABILITY= SCHEMA_ONLY | 28/26/30/ | 28 | 38/38/37 | 37,7 |
| Disk table | 614/605/596 | 605 | 633/637/634 | 634,67 |
По результатам тестирования:
Наиболее интересные результаты выделил желтым цветом. В целом вставка в In-Memory таблиц смотрится хорошо, можно заметить, что в MS SQL Server 2014 она даже быстрее чем в 2016, видно из-за того, что в 2016 было снято множество ограничений, что немного повлияло на скорость. По таблице заметен выигрыш Native Compiled процедур.
Тесты «Table with DURABILITY = SCHEMA_AND_DATA, UNICODE, не BIN поле» -это тестирование в MS SQL Server 2016 с полями таблицы не UNICODE и не BIN collation видно, что они не сильно влияют на скорость, но заметно что не BIN и не UNICODE полей и при DURABILITY = SCHEMA_AND_DATA данные чуть ниже, возможно из-за меньших типов данных при хранении.
По результатам Table with DURABILITY = SCHEMA_AND_DATA и Disk table результаты не сильно отличаются в пользу In-memory таблиц. У меня disk table таблицы и файлы файловой группы In-Memory расположены на одних дисках, так что все упирается в них. На практике, для данных таблиц In-Memory желательно выделять отдельный диск, а лучше SSD диск, тогда производительность таблиц In-Memory будет заметна. К примеру, у вас есть база данных 1 тб, вы покупаете отдельный диски 120 Гб , строите Raid массив, и располагаете на них вашу файловую группу In-Memory, то в данном случае мы получим довольно хороший выигрыш.
Тесты запускались больше количество раз, чем указано выше в таблице, все результаты были в этих границах.
Наблюдение таблиц In-Memory
Ниже несколько запрос по получению информации по таблицам In-Memory на вашем сервере:
Получение общей информации, сколько таблицы занимают в памяти:
в 2 раза лучше, чем при появившейся в SQL Server 2008 page-компрессии), чтобы утрамбовать больше данных в память. Традиционно от колоночных индексов выигрывает OLAP, потому что, как мы помним, это массивное чтение. Как правило, требуется прочитать вдоль по строкам (или по диапазону) все колонки, по которым справочники (таблицы измерений, лучи звезды) связаны с колонками внешних ключей в таблице фактов (ступице), чтобы построить между ними join (или semi-join). В SQL Server 2012 в этом плане произошли две полезные вещи. Во-первых, xVelocity (бывш. VertiPaq) появилась в Analysis Services в виде так называемых табличных моделей (Tabular Model), альтернативных традиционным многомерным, существовавшим еще, дай Б-г памяти, с SQL Server 7.0. Во-вторых, колоночный индекс перестал быть вещью в себе, и его стало возможно построить по мере надобности явно — в T-SQL появилась команда CREATE [NONCLUSTERED] COLUMNSTORE INDEX. На колоночные индексы сразу была наложена туча ограничений, самым жестоким из которых было, конечно, вот это — UPDATE statement failed because data cannot be updated in a table that has a nonclustered columnstore index. Consider disabling the columnstore index before issuing the UPDATE statement, and then rebuilding the columnstore index after UPDATE has completed. В SQL Server 2014 это зло побороли при помощи обновляемого кластерного колоночного индекса. Ну как колоночного… Чтобы сделать колоночный индекс обновляемым, на него навесили delta store и delete bitmap. Когда запись удаляется, она физически не исчезает, а на нее взводится флажок в delete bitmap. Когда происходит вставка записи, она попадает в delta store. И то, и другое — обычные B-Tree (rowstore) со всеми вытекающими плюсами и минусами. Есть фоновый процесс Tuple Mover, который ползает по delta store и конвертирует добавленные записи в сегменты columnstore, но, вообще говоря, чтение колоночного индекса означает чтение не только columnstore, но еще и этих двух друзей-довесков, потому как требуется отфильтровать удаленные записи и сделать union добавленных. Тем не менее, через две недели после своего выхода SQL Sever 2014 продемонстрировал рекордные результаты в независимых аналитических тестах TPC-H, заняв первые строчки в турнирных таблицах по весовым категориям 1, 3 и 10 ТБ объема БД в некластерном (standalone) зачете. Таким образом, будем считать, что с in-memory OLAP все обстоит замечательно и перейдем к in-memory OLTP.
Как уже говорилось, Hekaton — это не кодовое название очередной версии SQL Server, как были Денали, Катмай, Юкон и т.д., а, собственно, проект по разработке in-memory движка, т.е. составной части продукта. Этот компонент является наиболее ярким нововведением не только в текущей версии, но и, возможно, в масштабе всей линейки продуктов, начиная с 16-битного Ashton-Tate/Microsoft SQL Server 1.0, увидевшего свет 25 лет назад. Гекатон — слово греческое и означает сто или сам-сто = в сто раз, что кагбэ намекает, что это не придрацца круче в сравнении с тем, у кого всего в десять. Хотелось бы сразу предостеречь от заблуждения, что Гекатон — некий расширенный вариант dbcc pintable, потому что с прикрепленной к памяти таблицей работа происходит, как с обычной дисковой, включая планы выполнения, обеспечение транзакционной целостности с помощью блокировок и т.д. Гекатон — компактное самостоятельное ядро, интегрированное внутрь исполнительного механизма SQL Server, характеризующееся по сравнению с традиционным database engine отсутствием интепретируемых планов выполнения, блокировок как средства обеспечения логической целостности данных и латчей для физической целостности. Напомню, что латчи (не знаю, как они идеологически верно переводятся на русский, наверно, защелки) — это легковесные блокировки, которые накладываются на страницы данных, индексные страницы, какие-то служебные структуры нпосредственно в момент их чтения или изменения в памяти в отличие от блокировок, которые могут действовать на протяжении всей транзакции. Поэтому, не погружаясь в детали, можно считать, что дедлатчей не бывает. Бывают нюансы, но не такие болезненные. Другое отличие состоит в том, что блокировками можно управлять (при пом. хинтов, уровня изоляции). Латчи находятся в сугубом ведении SQL Server. Я не буду подробно вдаваться в их внутреннее устройство, желающие могут обратиться к BOL или на страницу Евгения Хабарова. Я вообще не буду ударяться в теорию, давайте лучше перейдем к примерам.
Создадим БД и в ней файл-группу под in-memory OLTP.
Это файлстримоподобная файл-группа, в нее будут персиститься данные из памяти, а в процессе recovery. соответственно, читаться взад. Подобно clustered columnstore она состоит из дата-файлов, в которые последовательно пишутся вставленные в рез-те insert или update записи и дельта-файлов, в которых хранятся идентификаторы удаленных записей. Сначала изменения, как водится, отражаются в памяти, а при checkpoint блоками по 256К (в случае data) и 4К (delta) скидывается на диск, о чем делается отметка в журнале транзакций. Слияние пар data-delta происходит автоматически при достижении определенного размера и в зависимости от размера оперативной памяти, а также может делаться вручную процедурой sys.sp_xtp_merge_checkpoint_files. Подробнее об этом процессе можно прочитать здесь.
Таким образом, размещение таблиц в памяти не означает, что если сервер отрубился, все, что нажито непосильным трудом, все будет потеряно. In-Memory OLTP — полностью транзакционная технология и поддерживает средства отказоустойчивости, включая AlwaysOn.
В свежесозданной БД создадим таблицу, оптимизированную для работы в памяти.
Последняя опция как раз означает, что таблица будет размещена в памяти. Каждая MEMORY_OPTIMIZED таблица обязана иметь хотя бы один индекс.Общее число не должно превышать 8. Входящие в индек поля не должны быть nullable. Для входящих в индексы полей n(var)char должна использоваться коллация BIN2. Кластерных индексов, по определению, нет. По своей структуре классических B-Tree тоже. Для таблиц в памяти индексы бывают HASH (лучше подходит для точечного поиска) и RANGE (как следует из названия, лучше подходит для сканов по диапазонам).
Основным компонентом хэш-индекса служит так называемая таблица соответствий (mapping table), в одной колонке которой хранятся результаты применения хэш-функции к конкатенации полей, образующих индексный ключ, в другой — указатели на записи. Поскольку хэш-функция может давать одинаковые результаты (возникают коллизии) для совершенно разных значений аргумента (для близких они как раз обязаны различаться), это в действительности будут указатели на области памяти, где лежат цепочки переполнений. Каждая такая цепочка представяляет собой двунаправленный список. Основным параметром при создании хэш-индекса выступает bucket_count. Это число слотов в таблице соответствий. Чем меньше их будет, тем выше вероятность коллизии, тем длиннее цепочки переполнений будут расти из каждого хэша. Соответственно, очевидно, что оно должно быть не меньше, чем количество уникальных значений в индексном ключе. На самом деле, оно оценивается как количество уникальных значений, округленное вверх до следующей степени 2, и здесь подробно объясняется, почему.
Второй тип индекса, доступный in-memory, называется range (диапазонный) и очень напоминает классический кластерный. Его узлы образуют упорядоченную структуру, эффективную для сканов по диапазонам. Вместо B-Tree используется его модификация Bw-Tree, наиболее ярким отличием котороя, пожалуй, является то, что она не хранит указатели на повторяющиеся значения. Если в таблице имеется миллион одинаковых значений, классическое дерево будет тупо держать в листьях миллион указателей (на данные). Bw обходится в этом случае одним, что позволяет драматически (англоязычные авторы очень любят это слово) сэкономить место при засовывании этого хозяйства в память. Единственно, в этом случае снова возникают цепочки переполнений — мы же не храним указатели на все записи, как добраться до следующей с таким же значением ключа? Возникает ощущение, что никакой экономии нет, просто байты на ptr переложили с листьев в букеты. Но нет, читайте, почему это не так, здесь, а мы двинемся дальше и создадим еще одну таблицу.
Обратите внимание на последнюю опцию, выделенную жирным цветом. Она означает, что данные этой таблицы не будут сохранены между рестартами сервера (сама структура останется). Выше я говорил, что по поводу Гекатона существует заблуждение, будто все, что находится в памяти, при рестарте теряется. Так вот для данных таблиц это действительно так, но вы создаете их совершенно осознанно, чтобы уменьшить накладные расходы, в частности, на журналирование там, где это не нужно. Это своего рода аналог временных таблиц. К слову, табличные переменные в Гекатоне также поддерживаются. Они объявляются через предварительное создание табличного типа CREATE TYPE… AS TABLE… В отличие от обычных табличных переменных они хранятся, понятно, не в дисковой tempdb, а относятся к той базе, где были объявлены.
Размещаемые в памяти таблицы не поддерживают автоматическое обновление статистики, в частности, ALTER DATABASE… SET AUTO_UPDATE_STATISTICS ON. Также не работает
exec sp_autostats @tblname = ‘ShoppingCart’
Index Name AUTOSTATS Last Updated
[ix_UserId] OFF NULL
[PK__Shopping__7A789AE57302F83B] OFF NULL
exec sp_autostats @tblname = ‘ShoppingCart’, @flagc = ‘ON’
— Operations that require a change to the schema version, for example renaming, are not supported with memory optimized tables.
Однако статистику можно обновлять вручную: UPDATE STATISTICS dbo.ShoppingCart WITH FULLSCAN, NORECOMPUTE.
Вообще таблицы в памяти имеют тучу ограничений. Не поддерживается большинство табличных хинтов: Нет TABLOCK, XLOCK, PAGLOCK,… На NOLOCK не ругается, но и не реагирует, как будто его и нет. Динамические и keyset-курсоры молчаливо переводятся в static. Не поддерживаются операторы TRUNCATE TABLE и MERGE (когда таблица в памяти выступает назначением). Существуют ограничения на типы используемых полей. Подробно прочитать о них можно здесь, мы же, дабы не растраиваться, посмотрим, что у нас получилось.
В каталоге установки SQL Server C:Program FilesMicrosoft SQL Server. DATAxtp11 появилось две dll, которые называются xtp_t_11_ .dll. Это наши таблицы ShoppingCart и UserSession.
Встроенный компилятор преобразует T-SQL-определения таблиц и хранимых процедур в Cшный код (можно посмотреть в том же каталоге), из которого получается машинный. Соответствующие динамические библиотеки загружаются в память и линкуются внутрь SQL Serverного процесса. При рестарте SQL Server библиотеки компилируются и загружаются заново на основе каталожной информации из метаданных.
В следующей части планируется рассмотреть нативную компиляцию хранимых процедур, уровни изоляции транзакций в Гекатоне, блокировки, журналирование и общую производительность по сравнению с традиционными дисковыми объектами.





