Продолжаем изучать основы SQL, и пришло время поговорить о простых объединениях JOIN. И сегодня мы рассмотрим, как объединяются данные по средствам операторов LEFT JOIN, RIGHT JOIN, CROSS JOIN и INNER JOIN, другими словами, научимся писать запросы, которые объединяют данные, и как обычно изучать все это будем на примерах.

Объединения JOIN очень важны в SQL, так как без умения писать запросы с объединением данных разных объектов, просто не обойтись программисту SQL, да и просто админу который время от времени выгружает какие-то данные из базы данных, поэтому это относится к основам SQL и каждый человек, который имеет дело с SQL, должен иметь представление, что это такое.
Примечание! Все примеры будем писать в Management Studio SQL Server 2008.
Мы с Вами уже давно изучаем основы SQL, и если вспомнить начинали мы с оператора select, и вообще было уже много материала на этом сайте по SQL, например:
И много другого, даже уже рассматривали объединения union и union all, но, так или иначе, более подробно именно об объединениях join мы с Вами не разговаривали, поэтому сегодня мы восполним этот пробел в наших знаниях.
И начнем мы как обычно с небольшой теории.
Объединения JOIN — это объединение двух или более объектов базы данных по средствам определенного ключа или ключей или в случае cross join и вовсе без ключа. Под объектами здесь подразумевается различные таблицы, представления (views), табличные функции или просто подзапросы sql, т.е. все, что возвращает табличные данные.
Содержание
- Объединение SQL LEFT и RIGHT JOIN
- Объединение SQL INNER JOIN
- Объединение SQL CROSS JOIN
- Содержание
- Описание оператора [ править | править код ]
- Виды оператора JOIN [ править | править код ]
- Начало: одна таблица, никакого JOIN
- Логика, стоящая за соединением таблиц
- INNER JOIN
- FULL JOIN
- LEFT JOIN
- RIGHT JOIN
- CROSS JOIN
- SELF JOIN
- Исключение пересечения множеств
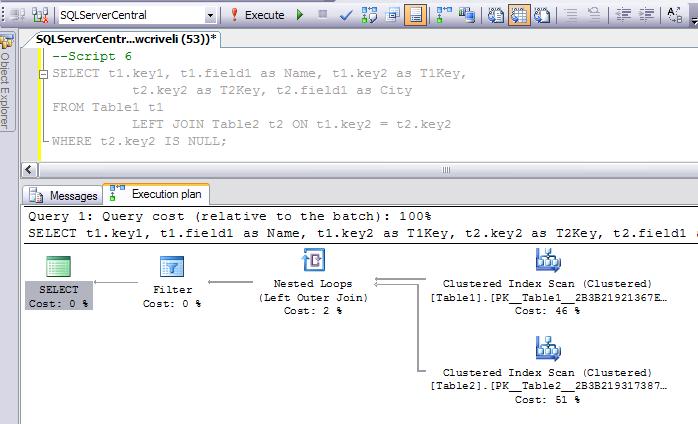
- Слово о планах исполнения
- JOIN и индексы
- Неравенства
Объединение SQL LEFT и RIGHT JOIN
LEFT JOIN – это объединение данных по левому ключу, т.е. допустим, мы объединяем две таблицы по left join, и это значит что все данные из второй таблицы подтянутся к первой, а в случае отсутствия ключа выведется NULL значения, другими словами выведутся все данные из левой таблицы и все данные по ключу из правой таблицы.
RIGHT JOIN – это такое же объединение как и Left join только будут выводиться все данные из правой таблицы и только те данные из левой таблицы в которых есть ключ объединения.
Теперь давайте рассматривать примеры, и для начала создадим две таблицы:
Вот такие простенькие таблицы, И я для примера заполнил их вот такими данными:
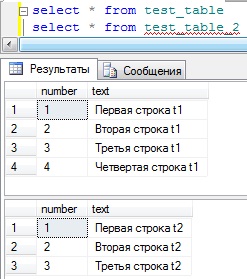
Теперь давайте напишем запрос с объединением этих таблиц по ключу number, для начала по LEFT:
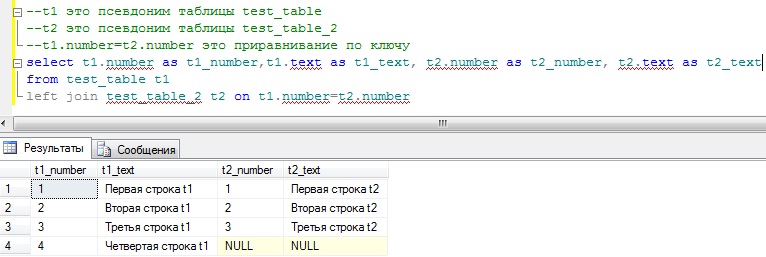
Как видите, здесь данные из таблицы t1 вывелись все, а данные из таблицы t2 не все, так как строки с number = 4 там нет, поэтому и вывелись NULL значения.
А что будет, если бы мы объединяли по средствам right join, а было бы вот это:
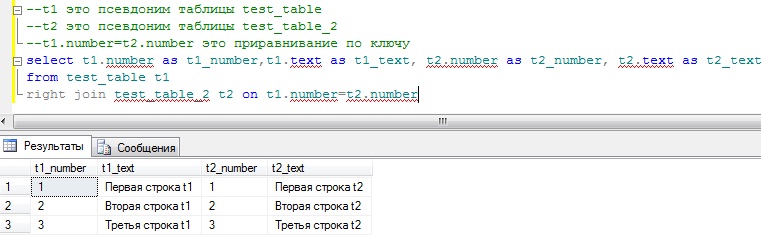
Другими словами, вывелись все строки из таблицы t2 и соответствующие записи из таблицы t1, так как все те ключи, которые есть в таблице t2, есть и в таблице t1, и поэтому у нас нет NULL значений.
Объединение SQL INNER JOIN
Inner join – это объединение когда выводятся все записи из одной таблицы и все соответствующие записи из другой таблице, а те записи которых нет в одной или в другой таблице выводиться не будут, т.е. только те записи которые соответствуют ключу. Кстати сразу скажу, что inner join это то же самое, что и просто join без Inner. Пример:
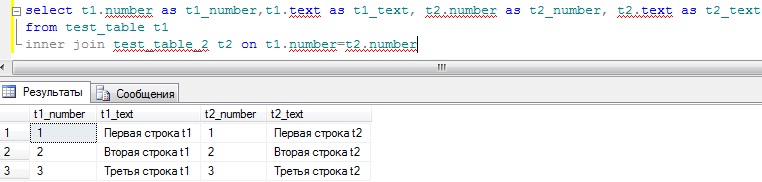
А теперь давайте попробуем объединить наши таблицы по двум ключам, для этого немного вспомним, как добавлять колонку в таблицу и как обновить данные через update, так как в наших таблицах всего две колонки, и объединять по текстовому полю как-то не хорошо. Для этого добавим колонки:
Обновим наши данные, просто проставим в колонку number2 значение 1:
И давайте напишем запрос с объединением по двум ключам:
И результат будет таким же, как и в предыдущем примере:
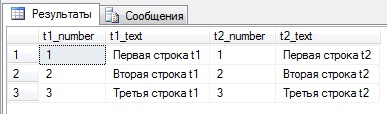
Но если мы, допустим во второй таблице в одной строке изменим, поле number2 на значение скажем 2, то результат будет уже совсем другой.
Запрос тот же самый, а вот результат:

Как видите, по второму ключу у нас одна строка не вывелась.
Объединение SQL CROSS JOIN
CROSS JOIN – это объединение SQL по которым каждая строка одной таблицы объединяется с каждой строкой другой таблицы. Лично у меня это объединение редко требуется, но все равно иногда требуется, поэтому Вы также должны уметь его использовать. Например, в нашем случае получится, конечно, не понятно что, но все равно давайте попробуем, тем более синтаксис немного отличается:
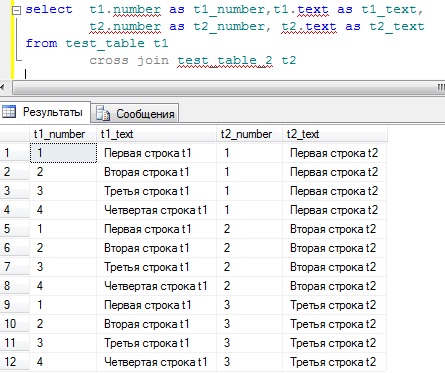
Здесь у нас каждой строке таблицы test_table соответствует каждая строка из таблицы test_table_2, т.е. в таблице test_table у нас 4 строки, а в таблице test_table_2 3 строки 4 умножить 3 и будет 12, как и у нас вывелось 12 строк.
И напоследок, давайте покажу, как можно объединять несколько таблиц, для этого я, просто для примера, несколько раз объединю нашу первую таблицу со второй, смысла в объединение в данном случае, конечно, нет но, Вы увидите, как можно это делать и так приступим:
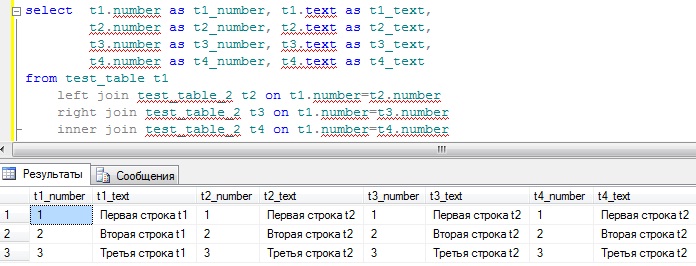
Как видите, я здесь объединяю и по left и по right и по inner просто, для того чтобы это было наглядно.
С объединениями я думаю достаточно, тем более ничего сложного в них нет. Но на этом изучение SQL не закончено в следующих статьях мы продолжим, а пока тренируйтесь и пишите свои запросы. Удачи!
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в предложение FROM операторов SELECT, UPDATE и DELETE.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор. Отличительными особенностями операции соединения являются следующие:
- в схему таблицы-результата входят столбцы обеих исходных таблиц (таблиц-операндов), то есть схема результата является «сцеплением» схем операндов;
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы-операнда со строкой второй таблицы-операнда.
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
При необходимости соединения не двух, а нескольких таблиц, операция соединения применяется несколько раз (последовательно).
SQL-операция JOIN является реализацией операции соединения реляционной алгебры только в некотором приближении, поскольку в реляционной модели данных соединение выполняется над отношениями, которые являются множествами, а в SQL — над таблицами, которые являются мультимножествами. Результаты операций тоже, в общем случае, различны: в реляционной алгебре результат соединения даёт отношение (множество), а в SQL — таблицу (мультимножество).
Содержание
Описание оператора [ править | править код ]
В большинстве СУБД при указании слов LEFT , RIGHT , FULL слово OUTER можно опустить. Слово INNER также в большинстве СУБД можно опустить.
В общем случае СУБД при выполнении соединения проверяет условие (предикат) condition. Если названия столбцов, по которым происходит соединение таблиц, совпадают, то вместо ON можно использовать USING . Для CROSS JOIN условие не указывается.
Для перекрёстного соединения (декартова произведения) CROSS JOIN в некоторых реализациях SQL используется оператор «запятая» (,):
Виды оператора JOIN [ править | править код ]
Для дальнейших пояснений будут использоваться следующие таблицы:
| Id | Name |
|---|---|
| 1 | Москва |
| 2 | Санкт-Петербург |
| 3 | Казань |
| Name | CityId |
|---|---|
| Андрей | 1 |
| Леонид | 2 |
| Сергей | 1 |
| Григорий | 4 |
INNER JOIN [ править | править код ]
Оператор внутреннего соединения INNER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
Описанный алгоритм действий является строго логическим, то есть он лишь объясняет результат, который должен получиться при выполнении операции, но не предписывает, чтобы конкретная СУБД выполняла соединение именно указанным образом. Существует несколько способов реализации операции соединения, например, соединение вложенными циклами (англ. inner loops join ), соединение хешированием (англ. hash join ), соединение слиянием (англ. merge join ). Единственное требование состоит в том, чтобы любая реализация логически давала такой же результат, как при применении описанного алгоритма.
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Сергей | 1 | 1 | Москва |
OUTER JOIN [ править | править код ]
Соединение двух таблиц, в результат которого обязательно входят все строки либо одной, либо обеих таблиц.
LEFT OUTER JOIN [ править | править код ]
Оператор левого внешнего соединения LEFT OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора важен, поскольку оператор не является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение левой и правой таблиц по предикату (условию) p.
- В результат включается внутреннее соединение ( INNER JOIN ) левой и правой таблиц по предикату p.
- Затем в результат добавляются те строки левой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие правой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Сергей | 1 | 1 | Москва |
| Григорий | 4 | NULL | NULL |
RIGHT OUTER JOIN [ править | править код ]
Оператор правого внешнего соединения RIGHT OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора важен, поскольку оператор не является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение левой и правой таблиц по предикату (условию) p.
- В результат включается внутреннее соединение ( INNER JOIN ) левой и правой таблиц по предикату p.
- Затем в результат добавляются те строки правой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие левой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Сергей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| NULL | NULL | 3 | Казань |
FULL OUTER JOIN [ править | править код ]
Оператор полного внешнего соединения FULL OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение первой и второй таблиц по предикату (условию) p. Слова «первой» и «второй» здесь не обозначают порядок в записи выражения (который неважен), а используются лишь для различения таблиц.
- В результат включается внутреннее соединение ( INNER JOIN ) первой и второй таблиц по предикату p.
- В результат добавляются те строки первой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие второй таблице, заполняются значениями NULL .
- В результат добавляются те строки второй таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких строк столбцы, соответствующие первой таблице, заполняются значениями NULL .
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Сергей | 1 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| NULL | NULL | 3 | Казань |
| Григорий | 4 | NULL | NULL |
CROSS JOIN [ править | править код ]
Оператор перекрёстного соединения, или декартова произведения CROSS JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является коммутативным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Каждая строка одной таблицы соединяется с каждой строкой второй таблицы, давая тем самым в результате все возможные сочетания строк двух таблиц.
| Person.Name | Person.CityId | City.Id | City.Name |
|---|---|---|---|
| Андрей | 1 | 1 | Москва |
| Андрей | 1 | 2 | Санкт-Петербург |
| Андрей | 1 | 3 | Казань |
| Леонид | 2 | 1 | Москва |
| Леонид | 2 | 2 | Санкт-Петербург |
| Леонид | 2 | 3 | Казань |
| Сергей | 1 | 1 | Москва |
| Сергей | 1 | 2 | Санкт-Петербург |
| Сергей | 1 | 3 | Казань |
| Григорий | 4 | 1 | Москва |
| Григорий | 4 | 2 | Санкт-Петербург |
| Григорий | 4 | 3 | Казань |
Если в предложении WHERE добавить условие соединения (предикат p), то есть ограничения на сочетания кортежей, то результат эквивалентен операции INNER JOIN с таким же условием:
Таким образом, выражения t1, t2 WHERE p и t1 INNER JOIN t2 ON p синтаксически являются альтернативными формами записи одной и той же логической операции внутреннего соединения по предикату p. Синтаксис CROSS JOIN + WHERE для операции соединения называют устаревшим, его не рекомендует стандарт SQL ANSI [1] [2] .
Автор: Wagner Crivelini
Опубликовано: 09.07.2010
Версия текста: 1.1
Первое, что мы узнаем об SQL – это как писать выражения SELECT для выборки данных из таблицы. Такие выражения выглядят просто и очень похоже на обычный разговорный язык.
Но настоящие запросы зачастую гораздо сложнее, чем простые выражения SELECT.
Во-первых, нужные данные обычно разбиты на несколько разных таблиц. Это естественное следствие нормализации данных, которая является характерным свойством любой хорошо спланированной модели БД. SQL позволяет объединить эти данные.
В прошлом администраторы БД и разработчики помещали все нужные таблицы и/или представления в оператор FROM, а затем использовали оператор WHERE, чтобы определить, как должны комбинироваться записи из одной таблицы с записями из другой (чтобы сделать этот текст чуть-чуть более читаемым, я в дальнейшем буду писать просто «таблица», а не «таблица и/или представление»).
Однако, чтобы стандартизовать объединение данных, понадобилось довольно много времени. Это было сделано с помощью оператора JOIN (ANSI-SQL 92). К сожалению, некоторые детали использования оператора JOIN так и остаются неизвестными очень многим.
Прежде чем показать различный синтаксис JOIN, поддерживаемый T-SQL (в SQL Server 2008), я опишу несколько концепций, которые не следует забывать при любом соединении данных из двух или нескольких таблиц.
Начало: одна таблица, никакого JOIN
Если запрос обращается только к одному объекту, синтаксис будет очень простым, и никакое соединение не потребуется. Выражение будет старым добрым " SELECT fields FROM object " с другими необязательными операторами (то есть WHERE, GROUP BY, HAVING или ORDER BY).
Однако конечные пользователи не знают, что администраторы БД обычно прячут множество сложных соединений за одним красивым и простым в использовании представлением. Это делается по разным причинам, от безопасности данных до производительности БД. Например, администратор может дать конечному пользователю разрешение на доступ к одному представлению вместо нескольких рабочих таблиц, что, очевидно, повышает сохранность данных. А если говорить о производительности, можно создать представление, используя правильные параметры для соединения записей из разных таблиц, правильно использовать индексы и тем самым повысит производительность запроса.
Как бы то ни было, соединения в БД всегда есть, даже если конечный пользователь их и не видит.
Логика, стоящая за соединением таблиц
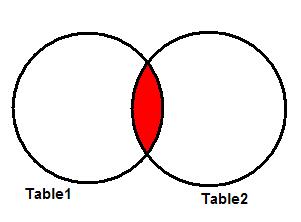
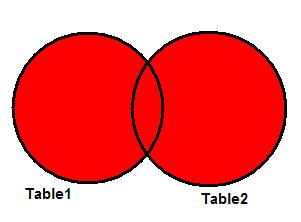
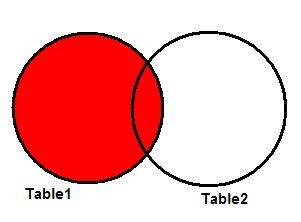
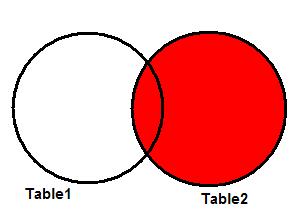
Много лет назад, когда я начинал работать с SQL, я узнал, что есть несколько типов соединения данных. Но мне потребовалось некоторое время, чтобы точно понять, что я делаю, соединяя таблицы. Возможно из-за того, что люди боятся математики, не часто можно услышать, что вся идея соединений таблиц – это теория множеств. Несмотря на заковыристое название, концепция так проста, что изучается в начальной школе.
Рисунок 1 очень похож на картинки из учебника для первого класса. Идея в том, чтобы найти в разных множествах соответствующие объекты. Это как раз то, чем занимается JOIN в SQL!
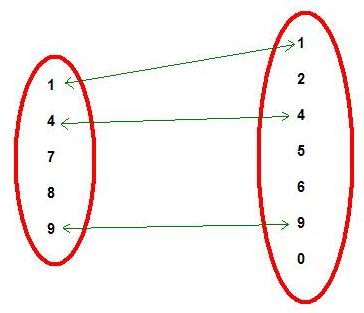
Рисунок 1. Комбинируем объекты из разных множеств.
Если вы поняли эту аналогию, все становится более осмысленным.
Представьте, что 2 множества на рисунке 1 – это таблицы, а цифры – это ключи, используемые для соединения таблиц. Таким образом, в каждом из множеств вместо целой записи мы видим только ключевые поля каждой таблицы. Результирующий набор комбинаций будет определяться типом используемого соединения, и это я как раз и собираюсь показать. Чтобы проиллюстрировать примеры, возьмем 2 таблицы, показанные ниже:
Таблица Table1
Таблица Table2