
Привет. Я задумывал эту заметку для студентов курса Digital Rockstar, на котором мы учим маркетологов автоматизировать свою работу с помощью программирования, но решил поделиться шпаргалкой по Pandas со всеми. Я ожидаю, что читатель умеет писать код на Python хотя бы на минимальном уровне, знает, что такое списки, словари, циклы и функции.
Что такое Pandas и зачем он нужен
Pandas — это библиотека для работы с данными на Python. Она упрощает жизнь аналитикам: где раньше использовалось 10 строк кода теперь хватит одной.
Например, чтобы прочитать данные из csv, в стандартном Python надо сначала решить, как хранить данные, затем открыть файл, прочитать его построчно, отделить значения друг от друга и очистить данные от специальных символов.
В Pandas всё проще. Во-первых, не нужно думать, как будут храниться данные — они лежат в датафрейме. Во-вторых, достаточно написать одну команду:
Pandas добавляет в Python новые структуры данных — серии и датафреймы. Расскажу, что это такое.
Структуры данных: серии и датафреймы
Серии — одномерные массивы данных. Они очень похожи на списки, но отличаются по поведению — например, операции применяются к списку целиком, а в сериях — поэлементно.
То есть, если список умножить на 2, получите тот же список, повторенный 2 раза.
А если умножить серию, ее длина не изменится, а вот элементы удвоятся.
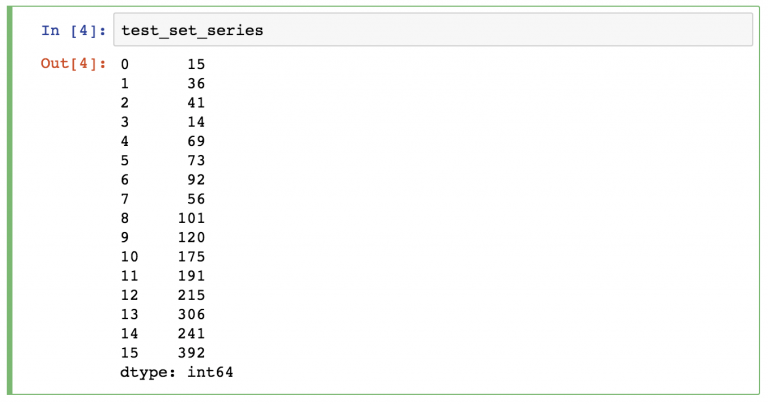
Обратите внимание на первый столбик вывода. Это индекс, в котором хранятся адреса каждого элемента серии. Каждый элемент потом можно получать, обратившись по нужному адресу.
Еще одно отличие серий от списков — в качестве индексов можно использовать произвольные значения, это делает данные нагляднее. Представим, что мы анализируем помесячные продажи. Используем в качестве индексов названия месяцев, значениями будет выручка:
Теперь можем получать значения каждого месяца:
Так как серии — одномерный массив данных, в них удобно хранить измерения по одному. На практике удобнее группировать данные вместе. Например, если мы анализируем помесячные продажи, полезно видеть не только выручку, но и количество проданных товаров, количество новых клиентов и средний чек. Для этого отлично подходят датафреймы.
Датафреймы — это таблицы. У их есть строки, колонки и ячейки.
Технически, колонки датафреймов — это серии. Поскольку в колонках обычно описывают одни и те же объекты, то все колонки делят один и тот же индекс:
Объясню, как создавать датафреймы и загружать в них данные.
Создаем датафреймы и загружаем данные
Бывает, что мы не знаем, что собой представляют данные, и не можем задать структуру заранее. Тогда удобно создать пустой датафрейм и позже наполнить его данными.
А иногда данные уже есть, но хранятся в переменной из стандартного Python, например, в словаре. Чтобы получить датафрейм, эту переменную передаем в ту же команду:
Случается, что в некоторых записях не хватает данных. Например, посмотрите на список goods_sold — в нём продажи, разбитые по товарным категориям. За первый месяц мы продали машины, компьютеры и программное обеспечение. Во втором машин нет, зато появились велосипеды, а в третьем снова появились машины, но велосипеды исчезли:
Если загрузить данные в датафрейм, Pandas создаст колонки для всех товарных категорий и, где это возможно, заполнит их данными:
Обратите внимание, продажи велосипедов в первом и третьем месяце равны NaN — расшифровывается как Not a Number. Так Pandas помечает отсутствующие значения.
Теперь разберем, как загружать данные из файлов. Чаще всего данные хранятся в экселевских таблицах или csv-, tsv- файлах.
Экселевские таблицы читаются с помощью команды pd.read_excel() . Параметрами нужно передать адрес файла на компьютере и название листа, который нужно прочитать. Команда работает как с xls, так и с xlsx:
Файлы формата csv и tsv — это текстовые файлы, в которых данные отделены друг от друга запятыми или табуляцией:
Оба читаются с помощью команды .read_csv() , символ табуляции передается параметром sep (от англ. separator — разделитель):
При загрузке можно назначить столбец, который будет индексом. Представьте, что мы загружаем таблицу с заказами. У каждого заказа есть свой уникальный номер, Если назначим этот номер индексом, сможем выгружать данные командой df[order_id] . Иначе придется писать фильтр df[df[‘ >.
О том, как получать данные из датафреймов, я расскажу в одном из следующих разделов. Чтобы назначить колонку индексом, добавим в команду read_csv() параметр index_col , равный названию нужной колонки:
После загрузки данных в датафрейм, хорошо бы их исследовать — особенно, если они вам незнакомы.
Исследуем загруженные данные
Представим, что мы анализируем продажи американского интернет-магазина. У нас есть данные о заказах и клиентах. Загрузим файл с продажами интернет-магазина в переменную orders . Раз загружаем заказы, укажем, что колонка id пойдет в индекс:
Расскажу о четырех атрибутах, которые есть у любого датафрейма: .shape , .columns , .index и .dtypes .
.shape показывает, сколько в датафрейме строк и колонок. Он возвращает пару значений (n_rows, n_columns) . Сначала идут строки, потом колонки.
В датафрейме 5009 строк и 5 колонок.
Окей, масштаб оценили. Теперь посмотрим, какая информация содержится в каждой колонке. С помощью .columns узнаем названия колонок:
Теперь видим, что в таблице есть дата заказа, метод доставки, номер клиента и выручка.
С помощью .dtypes узнаем типы данных, находящихся в каждой колонке и поймем, надо ли их обрабатывать. Бывает, что числа загружаются в виде текста. Если мы попробуем сложить две текстовых значения ‘1’ + ‘1’ , то получим не число 2, а строку ’11’ :
Тип object — это текст, float64 — это дробное число типа 3,14.
C помощью атрибута .index посмотрим, как называются строки:
Ожидаемо, в индексе датафрейма номера заказов: 100762, 100860 и так далее.
В колонке sales хранится стоимость каждого проданного товара. Чтобы узнать разброс значений, среднюю стоимость и медиану, используем метод .describe() :
Наконец, чтобы посмотреть на несколько примеров записей датафрейма, используем команды .head() и .sample() . Первая возвращает 6 записей из начала датафрейма. Вторая — 6 случайных записей:
Получив первое представление о датафреймах, теперь обсудим, как доставать из него данные.
Получаем данные из датафреймов
Данные из датафреймов можно получать по-разному: указав номера колонок и строк, использовав условные операторы или язык запросов. Расскажу подробнее о каждом способе.
Указываем нужные строки и колонки
Продолжаем анализировать продажи интернет-магазина, которые загрузили в предыдущем разделе. Допустим, я хочу вывести столбец sales . Для этого название столбца нужно заключить в квадратные скобки и поставить после них названия датафрейма: orders[‘sales’] :
Обратите внимание, результат команды — новый датафрейм с таким же индексом.
Если нужно вывести несколько столбцов, в квадратные скобки нужно вставить список с их названиями: orders[[‘customer_id’, ‘sales’]] . Будьте внимательны: квадратные скобки стали двойными. Первые — от датафрейма, вторые — от списка:
Перейдем к строкам. Их можно фильтровать по индексу и по порядку. Например, мы хотим вывести только заказы 100363, 100391 и 100706, для этого есть команда .loc[] :
А в другой раз бывает нужно достать просто заказы с 1 по 3 по порядку, вне зависимости от их номеров в таблицемы. Тогда используют команду .iloc[] :
Можно фильтровать датафреймы по колонкам и столбцам одновременно:
Часто вы не знаете заранее номеров заказов, которые вам нужны. Например, если задача — получить заказы, стоимостью более 1000 рублей. Эту задачу удобно решать с помощью условных операторов.
Если — то. Условные операторы
Задача: нужно узнать, откуда приходят самые большие заказы. Начнем с того, что достанем все покупки стоимостью более 1000 долларов:
Помните, в начале статьи я упоминал, что в сериях все операции применяются по-элементно? Так вот, операция orders[‘sales’] > 1000 идет по каждому элементу серии и, если условие выполняется, возвращает True . Если не выполняется — False . Получившуюся серию мы сохраняем в переменную filter_large .
Вторая команда фильтрует строки датафрейма с помощью серии. Если элемент filter_large равен True , заказ отобразится, если False — нет. Результат — датафрейм с заказами, стоимостью более 1000 долларов.
Интересно, сколько дорогих заказов было доставлено первым классом? Добавим в фильтр ещё одно условие:
Логика не изменилась. В переменную filter_large сохранили серию, удовлетворяющую условию orders[‘sales’] > 1000 . В filter_first_class — серию, удовлетворяющую orders[‘ship_mode’] == ‘First’ .
Затем объединили обе серии с помощью логического ‘И’: filter_first_class & filter_first_class . Получили новую серию той же длины, в элементах которой True только у заказов, стоимостью больше 1000, доставленных первым классом. Таких условий может быть сколько угодно.
Язык запросов
Еще один способ решить предыдущую задачу — использовать язык запросов. Все условия пишем одной строкой ‘sales > 1000 & ship_mode == ‘First’ и передаем ее в метод .query() . Запрос получается компактнее.
Отдельный кайф: значения для фильтров можно сохранить в переменной, а в запросе сослаться на нее с помощью символа @: sales > @sales_filter .
Разобравшись, как получать куски данных из датафрейма, перейдем к тому, как считать агрегированные метрики: количество заказов, суммарную выручку, средний чек, конверсию.
Считаем производные метрики
Задача: посчитаем, сколько денег магазин заработал с помощью каждого класса доставки. Начнем с простого — просуммируем выручку со всех заказов. Для этого используем метод .sum() :
Добавим класс доставки. Перед суммированием сгруппируем данные с помощью метода .groupby() :
3.514284e+05 — научный формат вывода чисел. Означает 3.51 * 10 5 . Нам такая точность не нужна, поэтому можем сказать Pandas, чтобы округлял значения до сотых:
Другое дело. Теперь видим сумму выручки по каждому классу доставки. По суммарной выручке неясно, становится лучше или хуже. Добавим разбивку по датам заказа:
Видно, что выручка прыгает ото дня ко дню: иногда 10 долларов, а иногда 378. Интересно, это меняется количество заказов или средний чек? Добавим к выборке количество заказов. Для этого вместо .sum() используем метод .agg() , в который передадим список с названиями нужных функций.
Ого, получается, что это так прыгает средний чек. Интересно, а какой был самый удачный день? Чтобы узнать, отсортируем получившийся датафрейм: выведем 10 самых денежных дней по выручке:
Команда разрослась, и её теперь неудобно читать. Чтобы упростить, можно разбить её на несколько строк. В конце каждой строки ставим обратный слеш :
В самый удачный день — 18 марта 2014 года — магазин заработал 27 тысяч долларов с помощью стандартного класса доставки. Интересно, откуда были клиенты, сделавшие эти заказы? Чтобы узнать, надо объединить данные о заказах с данными о клиентах.
Объединяем несколько датафреймов
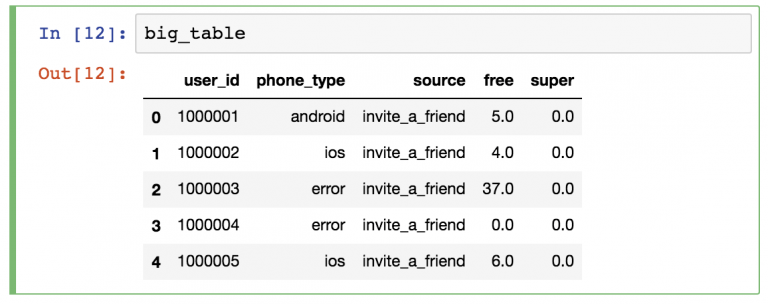
До сих пор мы смотрели только на таблицу с заказами. Но ведь у нас есть еще данные о клиентах интернет-магазина. Загрузим их в переменную customers и посмотрим, что они собой представляют:
Мы знаем тип клиента, место его проживания, его имя и имя контактного лица. У каждого клиента есть уникальный номер id . Этот же номер лежит в колонке customer_id таблицы orders . Значит мы можем найти, какие заказы сделал каждый клиент. Например, посмотрим, заказы пользователя CG-12520 :
Вернемся к задаче из предыдущего раздела: узнать, что за клиенты, которые сделали 18 марта заказы со стандартной доставкой. Для этого объединим таблицы с клиентами и заказами. Датафреймы объединяют с помощью методов .concat() , .merge() и .join() . Все они делают одно и то же, но отличаются синтаксисом — на практике достаточно уметь пользоваться одним из них.
Покажу на примере .merge() :
В .merge() я сначала указал названия датафреймов, которые хочу объединить. Затем уточнил, как именно их объединить и какие колонки использовать в качестве ключа.
Ключ — это колонка, связывающая оба датафрейма. В нашем случае — номер клиента. В таблице с заказами он в колонке customer_id , а таблице с клиентами — в индексе. Поэтому в команде мы пишем: left_on=’customer_ >.
Решаем задачу
Закрепим полученный материал, решив задачу. Найдем 5 городов, принесших самую большую выручку в 2016 году.
Для начала отфильтруем заказы из 2016 года:
Город — это атрибут пользователей, а не заказов. Добавим информацию о пользователях:
Cруппируем получившийся датафрейм по городам и посчитаем выручку:
Отсортируем по убыванию продаж и оставим топ-5:
Возьмите данные о заказах и покупателях и посчитайте:
- Сколько заказов, отправлено первым классом за последние 5 лет?
- Сколько в базе клиентов из Калифорнии?
- Сколько заказов они сделали?
- Постройте сводную таблицу средних чеков по всем штатам за каждый год.
Через некоторое время выложу ответы в Телеграме. Подписывайтесь, чтобы не пропустить ответы и новые статьи.
Кстати, большое спасибо Александру Марфицину за то, что помог отредактировать статью.
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
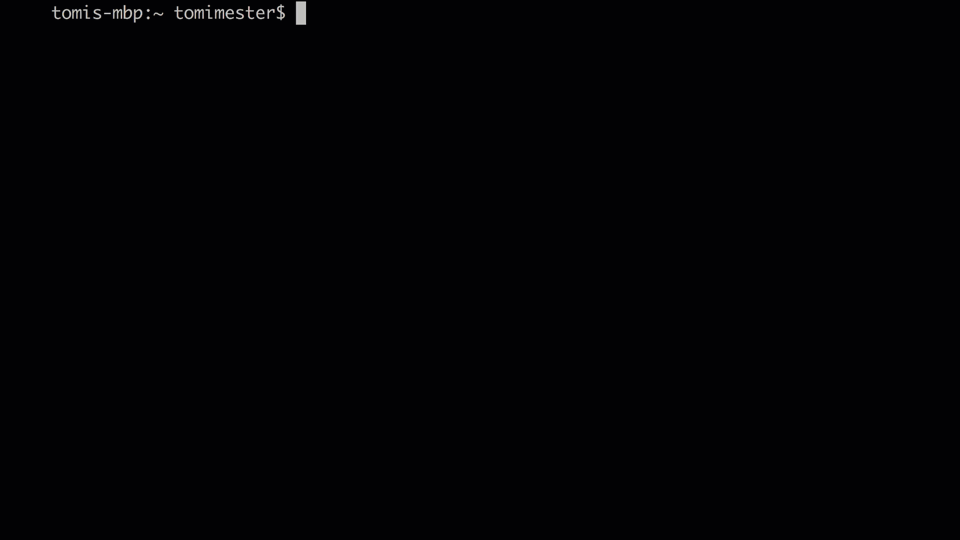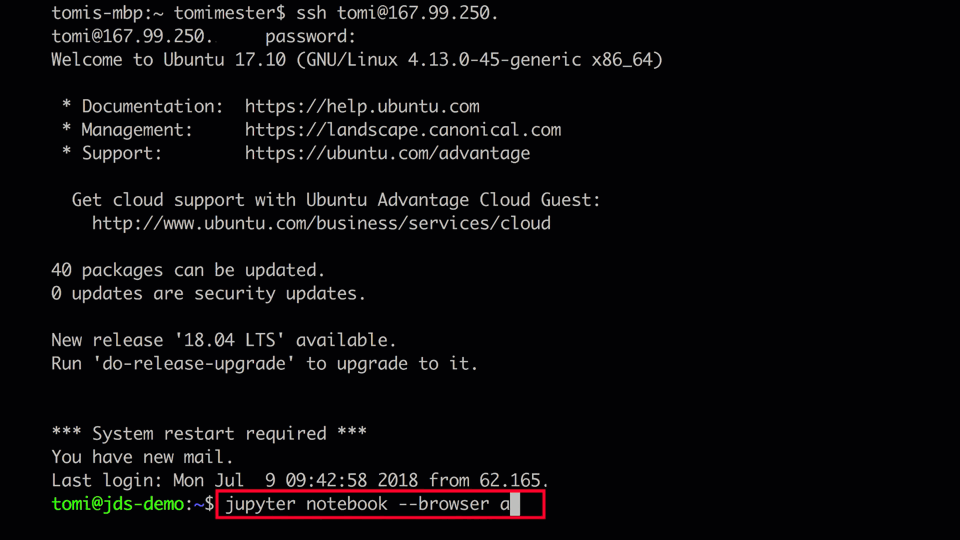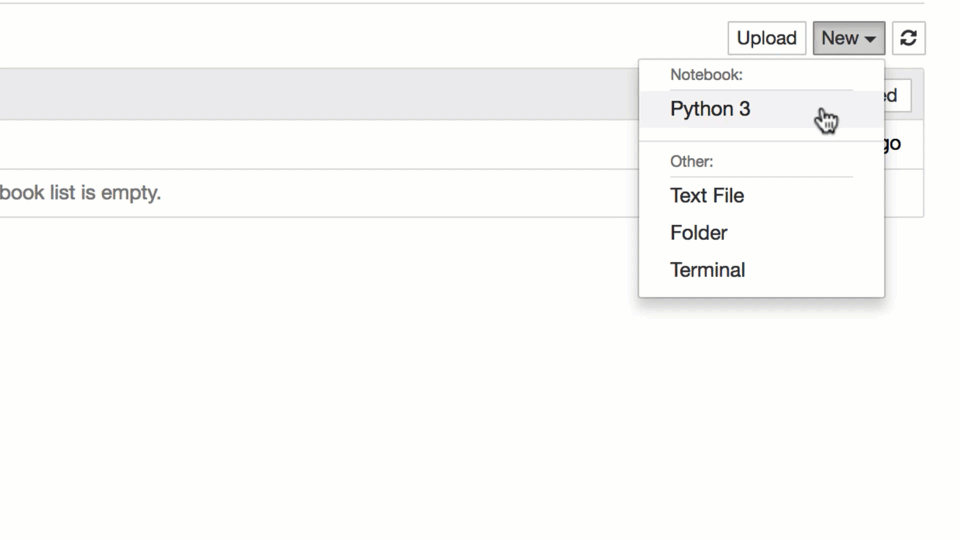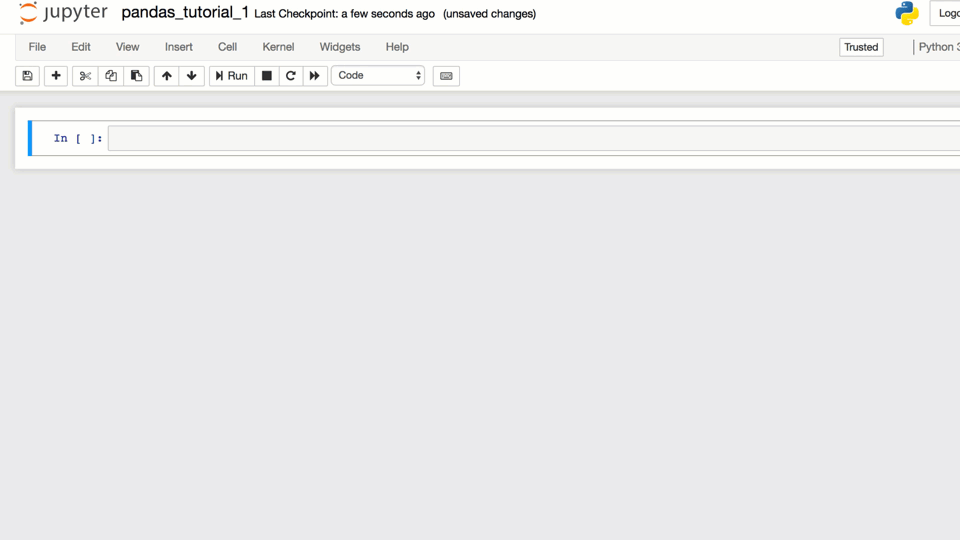
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».

- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:

Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть as pd , Jupyter Notebook понимает, что в будущем, при вводе pd подразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.
DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.
Тест на знание python



В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
Вернемся во вкладку “Home” http://you_ip:you_port/tree Jupyter для создания нового текстового файла…
затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…
…и назовем его zoo.csv!
Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
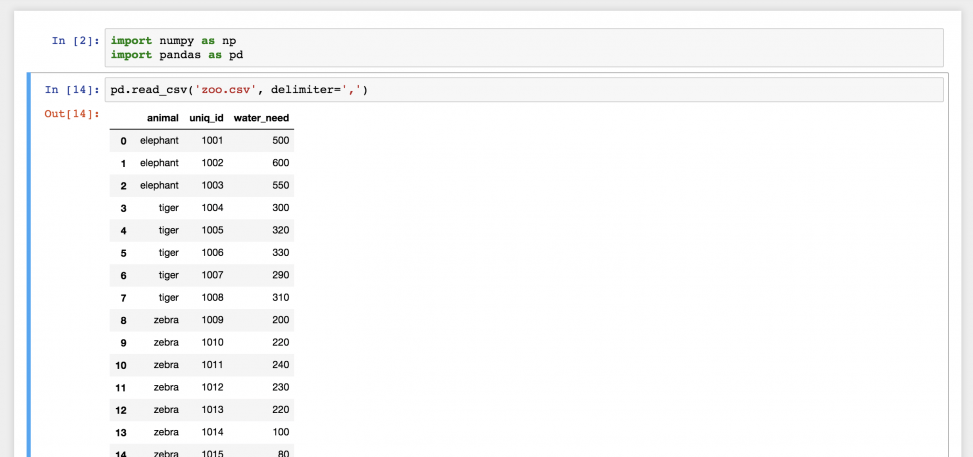
Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:
Если кликнуть на него…
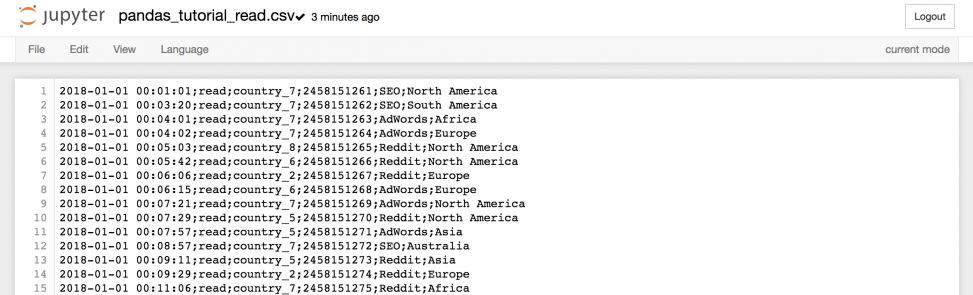
…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
Данные загружены в pandas!
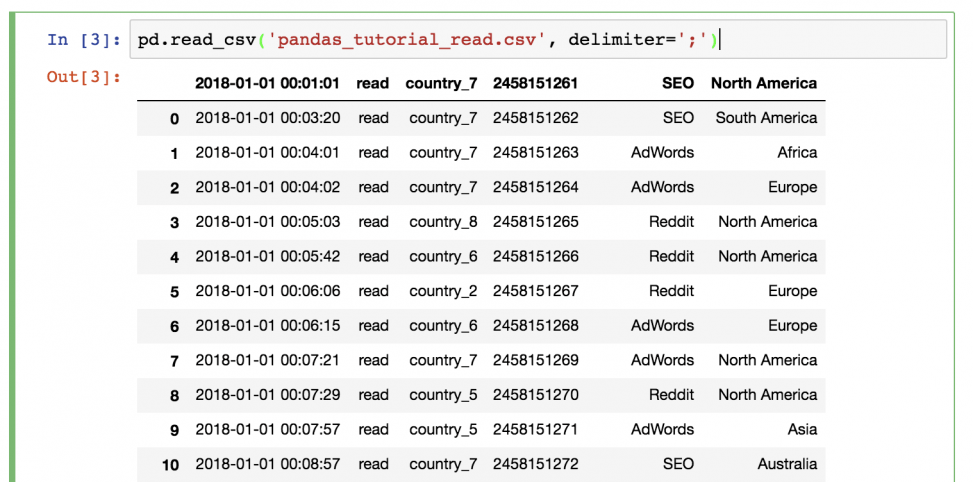
Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
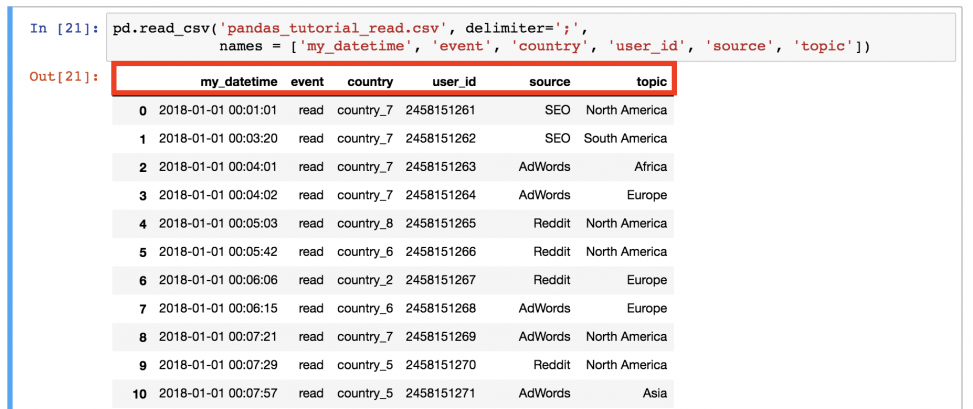
Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!
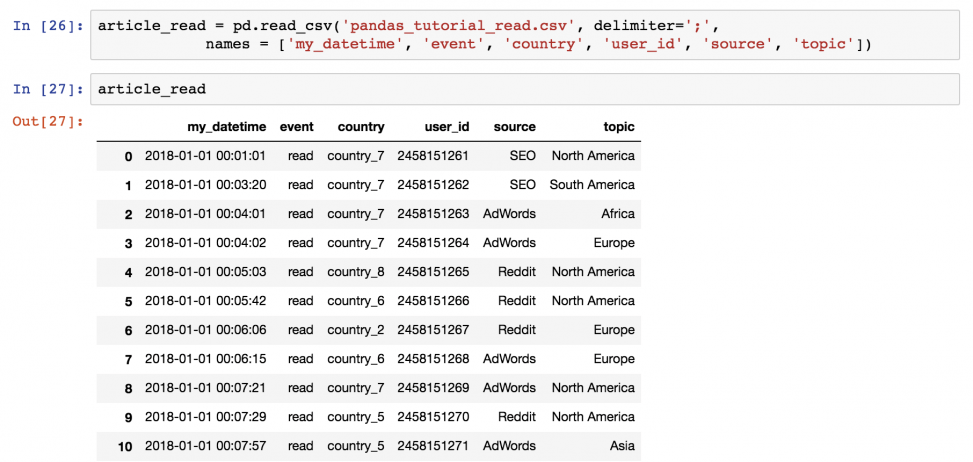
Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
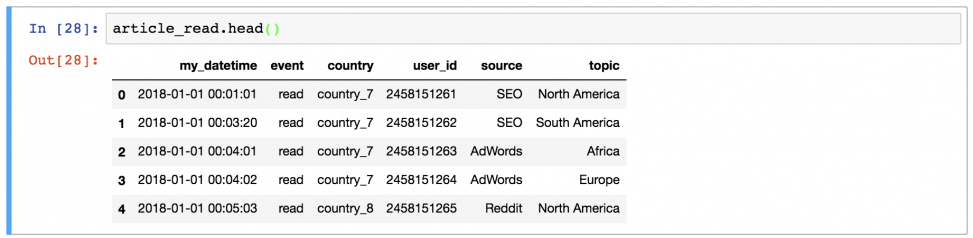
Или последние 5 строк:
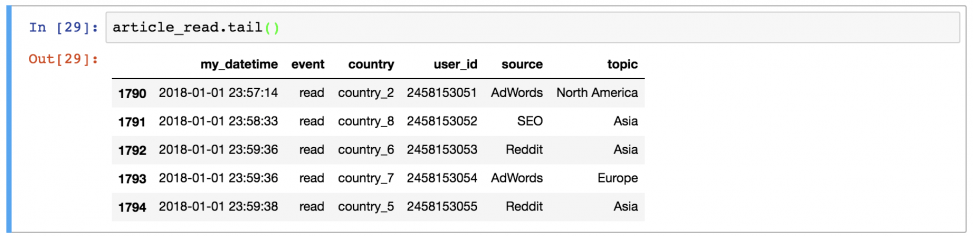
Или 5 случайных строк:
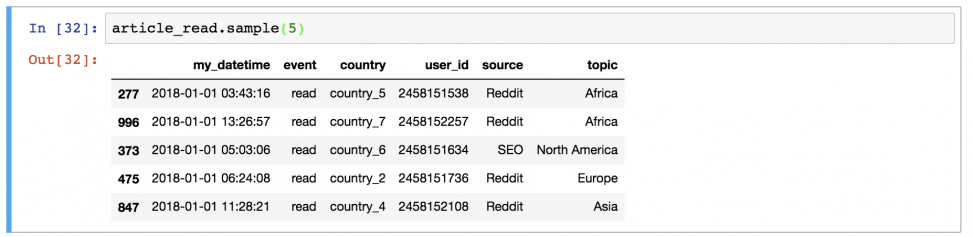
Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
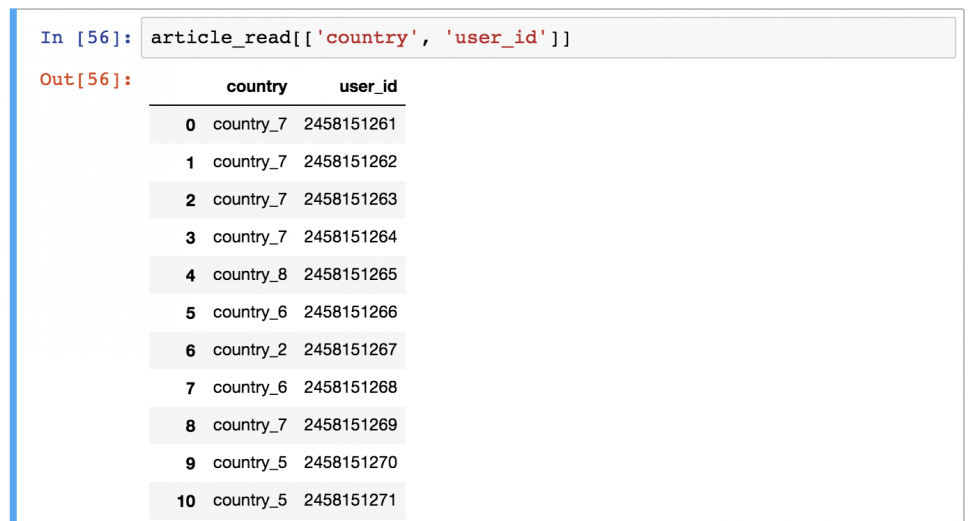
Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]
Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
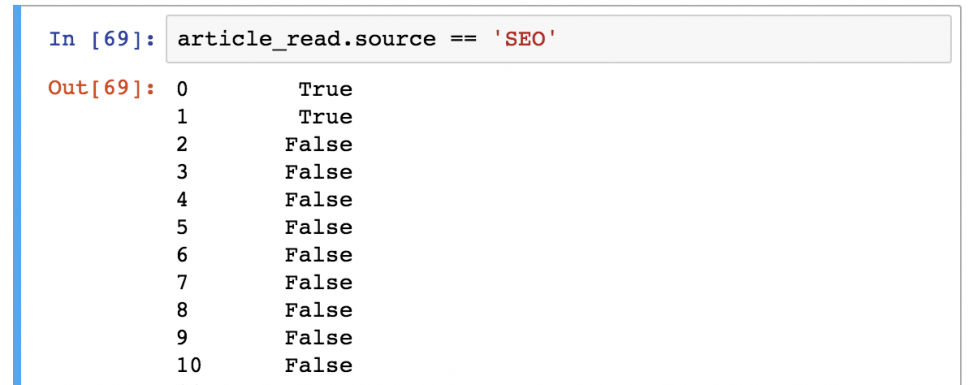
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли ‘SEO’ значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).
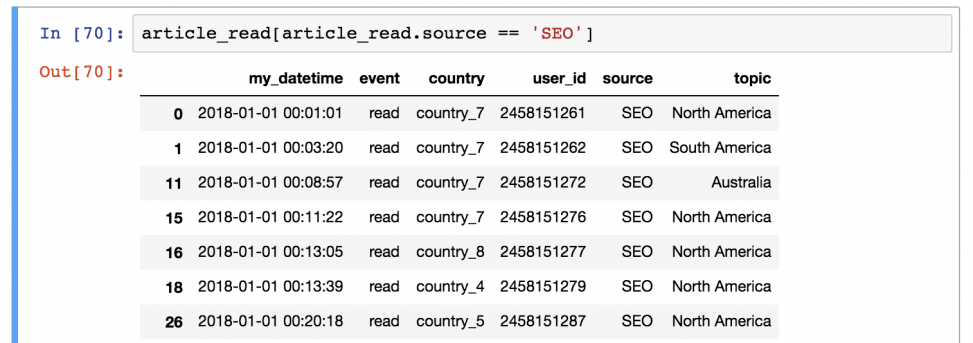
Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .
Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
Или, чтобы было понятнее, можно разбить на несколько строк:
В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == ‘country_2’] ). Потому берутся три нужные колонки ( [[‘user_id’, ‘topic’, ‘country’]] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
пример
Данные с заголовком, разделенные точками с запятой, а не запятыми
файл: table.csv
код:
выход :
Таблица без имен строк или индексов и запятых в качестве разделителей
файл: table.csv
код:
выход:
дальнейшее разъяснение можно найти на read_csv документации read_csv





